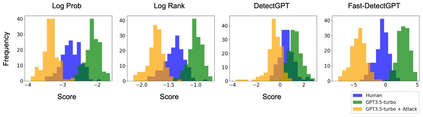
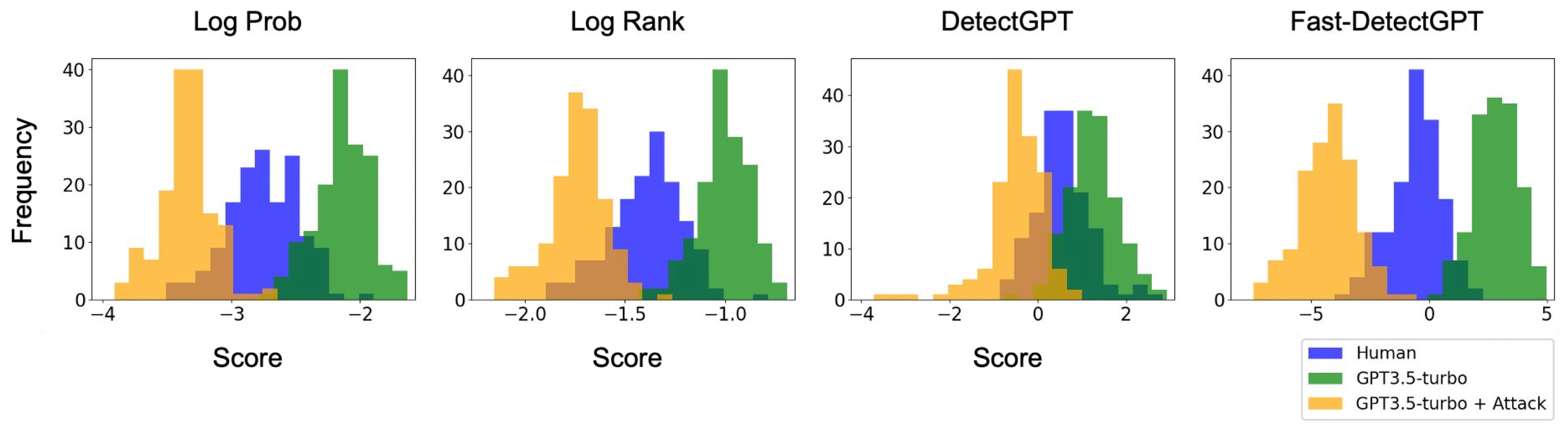
Large language models (LLMs) have exhibited remarkable fluency across various tasks. However, their unethical applications, such as disseminating disinformation, have become a growing concern. Although recent works have proposed a number of LLM detection methods, their robustness and reliability remain unclear. In this paper, we present RAFT: a grammar error-free black-box attack against existing LLM detectors. In contrast to previous attacks for language models, our method exploits the transferability of LLM embeddings at the word-level while preserving the original text quality. We leverage an auxiliary embedding to greedily select candidate words to perturb against the target detector. Experiments reveal that our attack effectively compromises all detectors in the study across various domains by up to 99%, and are transferable across source models. Manual human evaluation studies show our attacks are realistic and indistinguishable from original human-written text. We also show that examples generated by RAFT can be used to train adversarially robust detectors. Our work shows that current LLM detectors are not adversarially robust, underscoring the urgent need for more resilient detection mechanisms.
翻译:暂无翻译