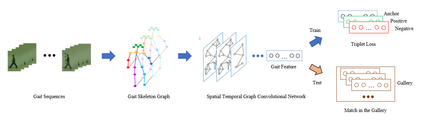
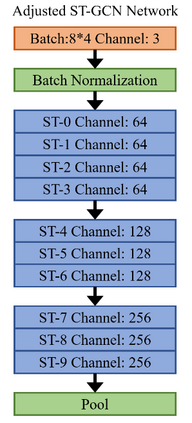
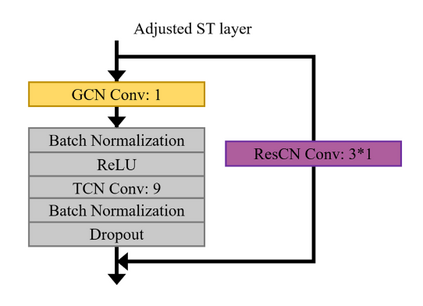
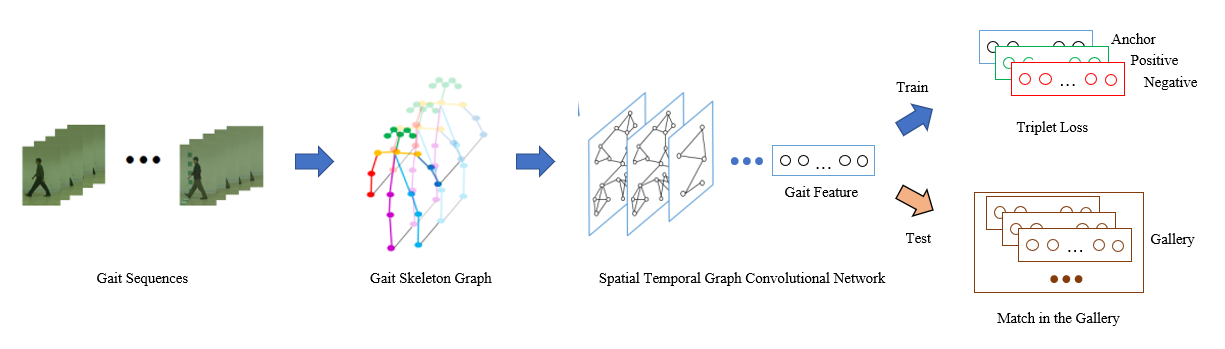
As an emerging biological identification technology, vision-based gait identification is an important research content in biometrics. Most existing gait identification methods extract features from gait videos and identify a probe sample by a query in the gallery. However, video data contains redundant information and can be easily influenced by bagging (BG) and clothing (CL). Since human body skeletons convey essential information about human gaits, a skeleton-based gait identification network is proposed in our project. First, extract skeleton sequences from the video and map them into a gait graph. Then a feature extraction network based on Spatio-Temporal Graph Convolutional Network (ST-GCN) is constructed to learn gait representations. Finally, the probe sample is identified by matching with the most similar piece in the gallery. We tested our method on the CASIA-B dataset. The result shows that our approach is highly adaptive and gets the advanced result in BG, CL conditions, and average.
翻译:作为新兴的生物识别技术,目视行踪识别是生物鉴别学的一个重要研究内容。多数现有的行迹识别方法从行迹视频中提取特征,并通过在画廊的查询来识别探针样本。然而,视频数据包含多余的信息,很容易受包装(BG)和服装(CL)的影响。由于人体骨骼传递了有关人类行踪的基本信息,因此在我们的项目中提议了一个基于骨架的行踪识别网络。首先,从视频中提取骨架序列并将其映入行迹图。然后,根据Spatio-时空图演动网络(ST-GCN)建立地貌提取网络,以学习行踪展示。最后,通过与画廊中最相似的作品进行匹配,确定了探样样。我们在CASIA-B数据集中测试了我们的方法。结果显示,我们的方法具有高度的适应性,并在BG、CL条件和平均中取得了先进的结果。