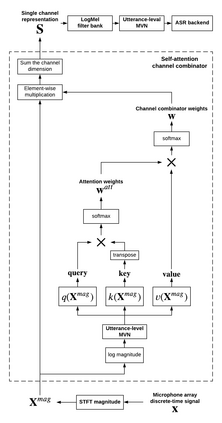
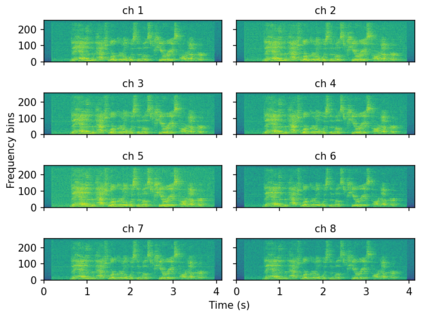
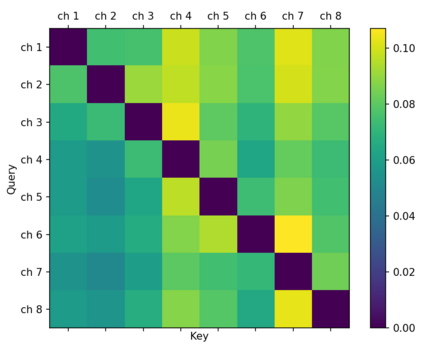
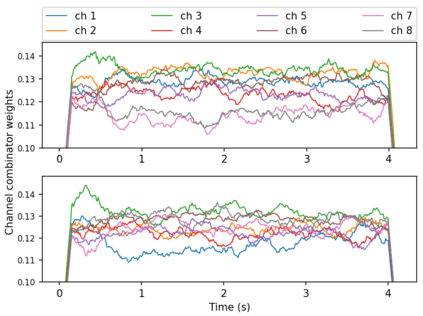
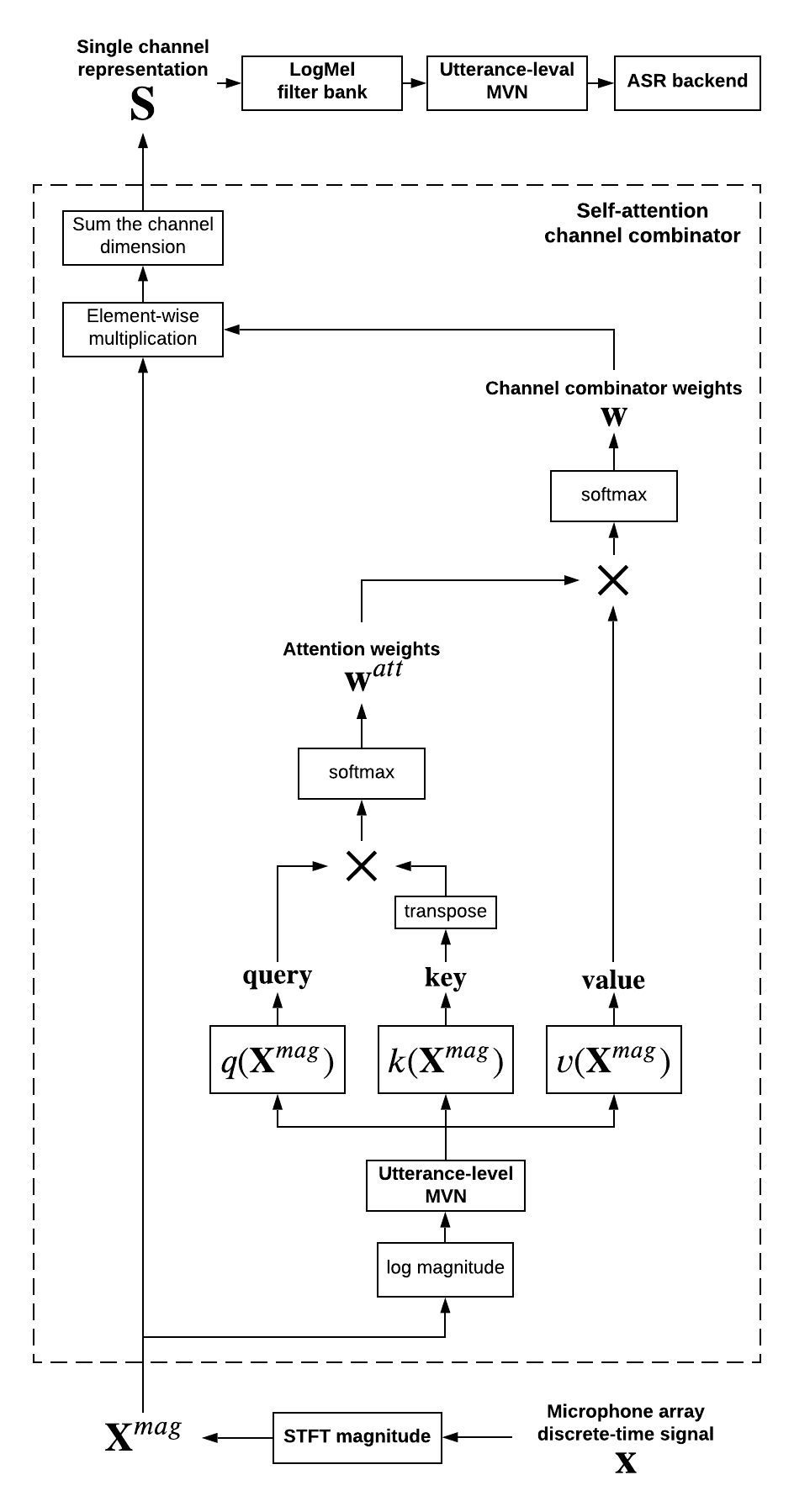
When a sufficiently large far-field training data is presented, jointly optimizing a multichannel frontend and an end-to-end (E2E) Automatic Speech Recognition (ASR) backend shows promising results. Recent literature has shown traditional beamformer designs, such as MVDR (Minimum Variance Distortionless Response) or fixed beamformers can be successfully integrated as the frontend into an E2E ASR system with learnable parameters. In this work, we propose the self-attention channel combinator (SACC) ASR frontend, which leverages the self-attention mechanism to combine multichannel audio signals in the magnitude spectral domain. Experiments conducted on a multichannel playback test data shows that the SACC achieved a 9.3% WERR compared to a state-of-the-art fixed beamformer-based frontend, both jointly optimized with a ContextNet-based ASR backend. We also demonstrate the connection between the SACC and the traditional beamformers, and analyze the intermediate outputs of the SACC.
翻译:当提出足够大的远方培训数据时,共同优化多通道前端和端对端自动语音识别(E2E)后端显示有希望的结果。最近的一些文献显示传统光束设计,如MVDR(最小差异无扭曲反应)或固定光束,可以成功地作为前端并入E2E ASR系统,具有可学习的参数。在这项工作中,我们提议采用自我注意频道组合器(SCAC)ASR前端,利用自留机制将光谱范围内的多频道音频信号结合起来。在多频道回放测试数据上进行的实验显示,SACC取得了9.3%的WERR,而后者与最先进的固定的固定光谱基前端相比,两者都与基于内联网的ASR后端共同优化。我们还演示了SACC与传统信号的连接器之间的联系,并分析了SACC的中间输出。