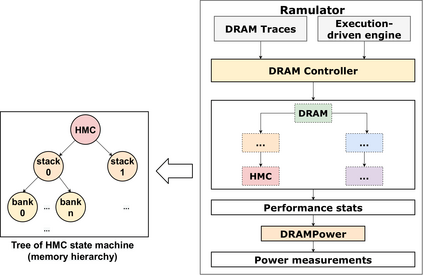
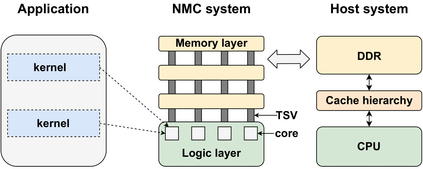
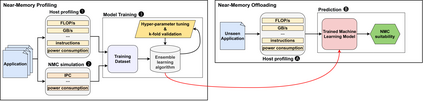
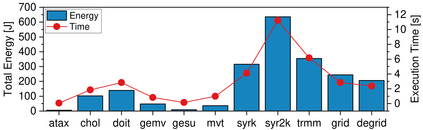
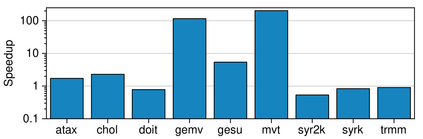
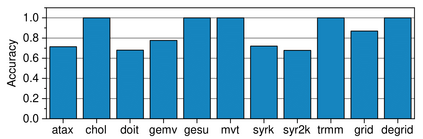
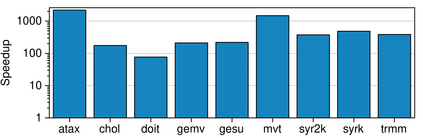
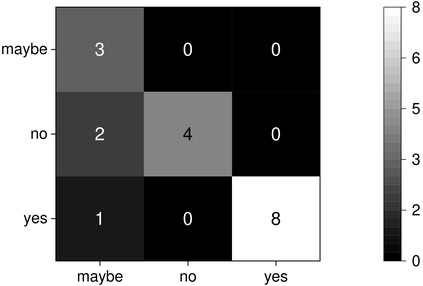
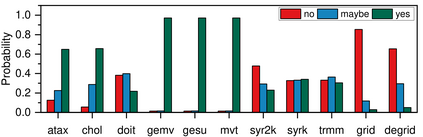
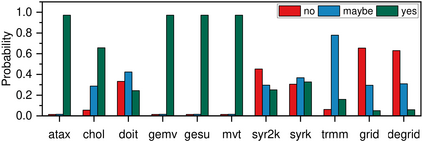
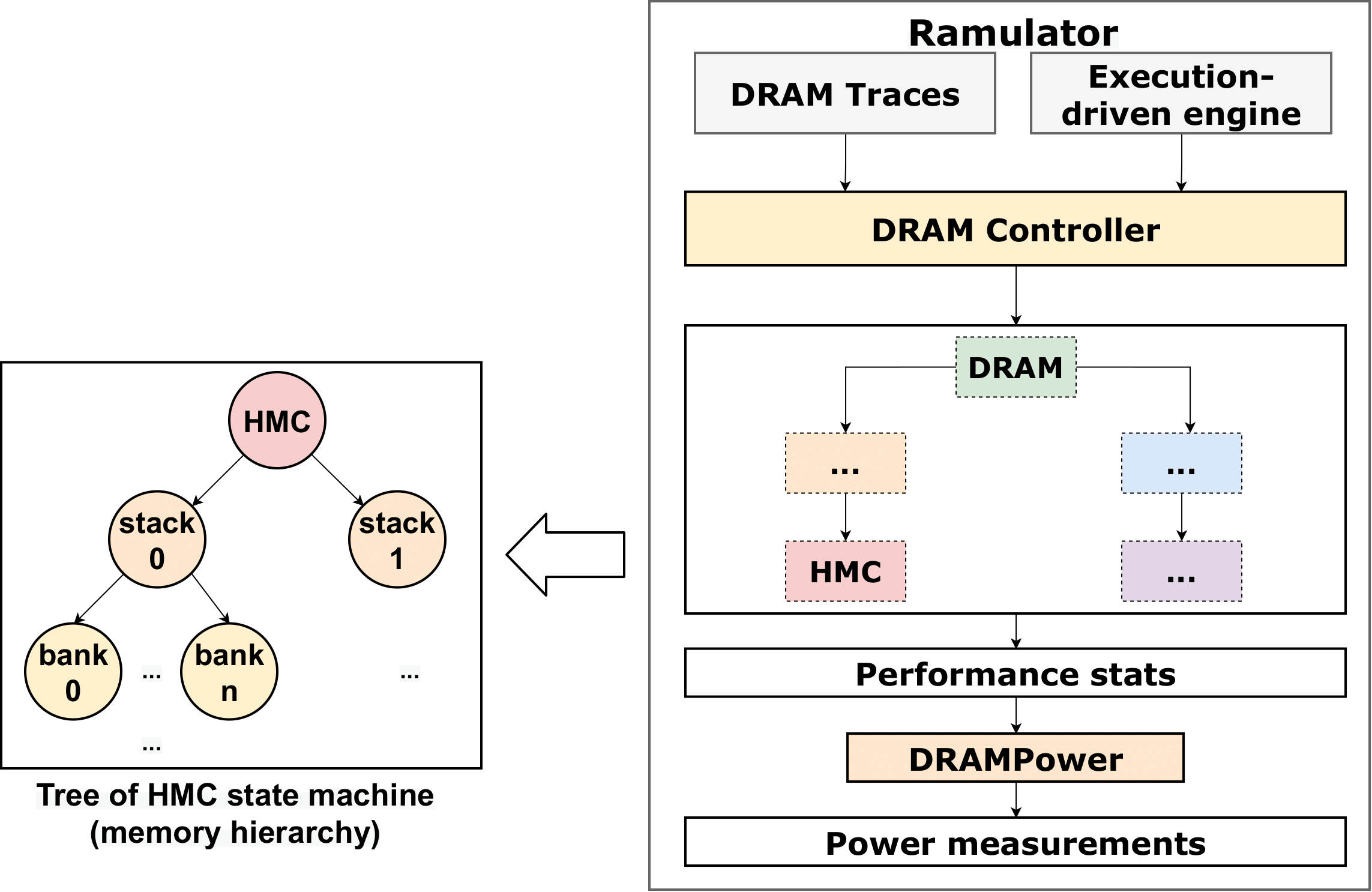
Real-world applications are now processing big-data sets, often bottlenecked by the data movement between the compute units and the main memory. Near-memory computing (NMC), a modern data-centric computational paradigm, can alleviate these bottlenecks, thereby improving the performance of applications. The lack of NMC system availability makes simulators the primary evaluation tool for performance estimation. However, simulators are usually time-consuming, and methods that can reduce this overhead would accelerate the early-stage design process of NMC systems. This work proposes Near-Memory computing Profiling and Offloading (NMPO), a high-level framework capable of predicting NMC offloading suitability employing an ensemble machine learning model. NMPO predicts NMC suitability with an accuracy of 85.6% and, compared to prior works, can reduce the prediction time by using hardware-dependent applications features by up to 3 order of magnitude.
翻译:目前,现实世界应用程序正在处理大数据集,往往被计算单位和主内存之间的数据流动所阻碍。近模计算(NMC)是现代以数据为中心的计算模式,可以缓解这些瓶颈,从而改善应用程序的性能。由于缺乏NMC系统,模拟器成为业绩估计的主要评价工具。不过,模拟器通常耗时,而能够减少这一间接费用的方法将加速NMC系统的早期设计过程。这项工作提出近模计算分析和卸载(NMPO),这是一个高层次框架,能够利用一个混合机器学习模型预测NMC的不适性。NMC预测准确性为85.6%,与先前的工程相比,通过使用依靠硬件的应用特征,可以缩短预测时间,最多达到3个数量级。