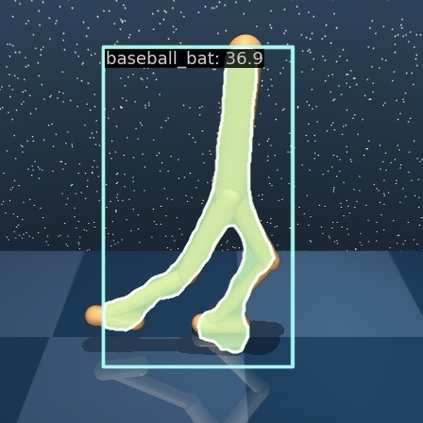
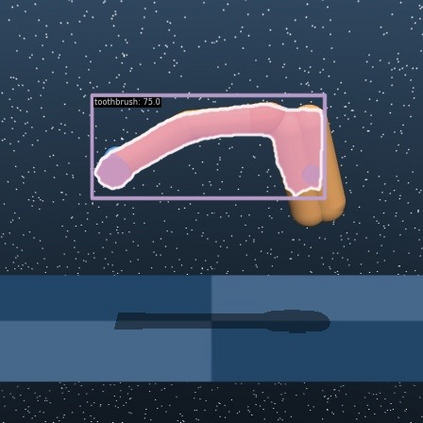
Learning policies that can generalize to unseen environments is a fundamental challenge in visual reinforcement learning (RL). While most current methods focus on acquiring robust visual representations through auxiliary supervision, pre-training, or data augmentation, the potential of modern vision foundation models remains underleveraged. In this work, we introduce Segment Anything Model for Generalizable visual RL (SAM-G), a novel framework that leverages the promptable segmentation ability of Segment Anything Model (SAM) to enhance the generalization capabilities of visual RL agents. We utilize image features from DINOv2 and SAM to find correspondence as point prompts to SAM, and then SAM produces high-quality masked images for agents directly. Evaluated across 8 DMControl tasks and 3 Adroit tasks, SAM-G significantly improves the visual generalization ability without altering the RL agents' architecture but merely their observations. Notably, SAM-G achieves 44% and 29% relative improvements on the challenging video hard setting on DMControl and Adroit respectively, compared to state-of-the-art methods. Video and code: https://yanjieze.com/SAM-G/
翻译:暂无翻译