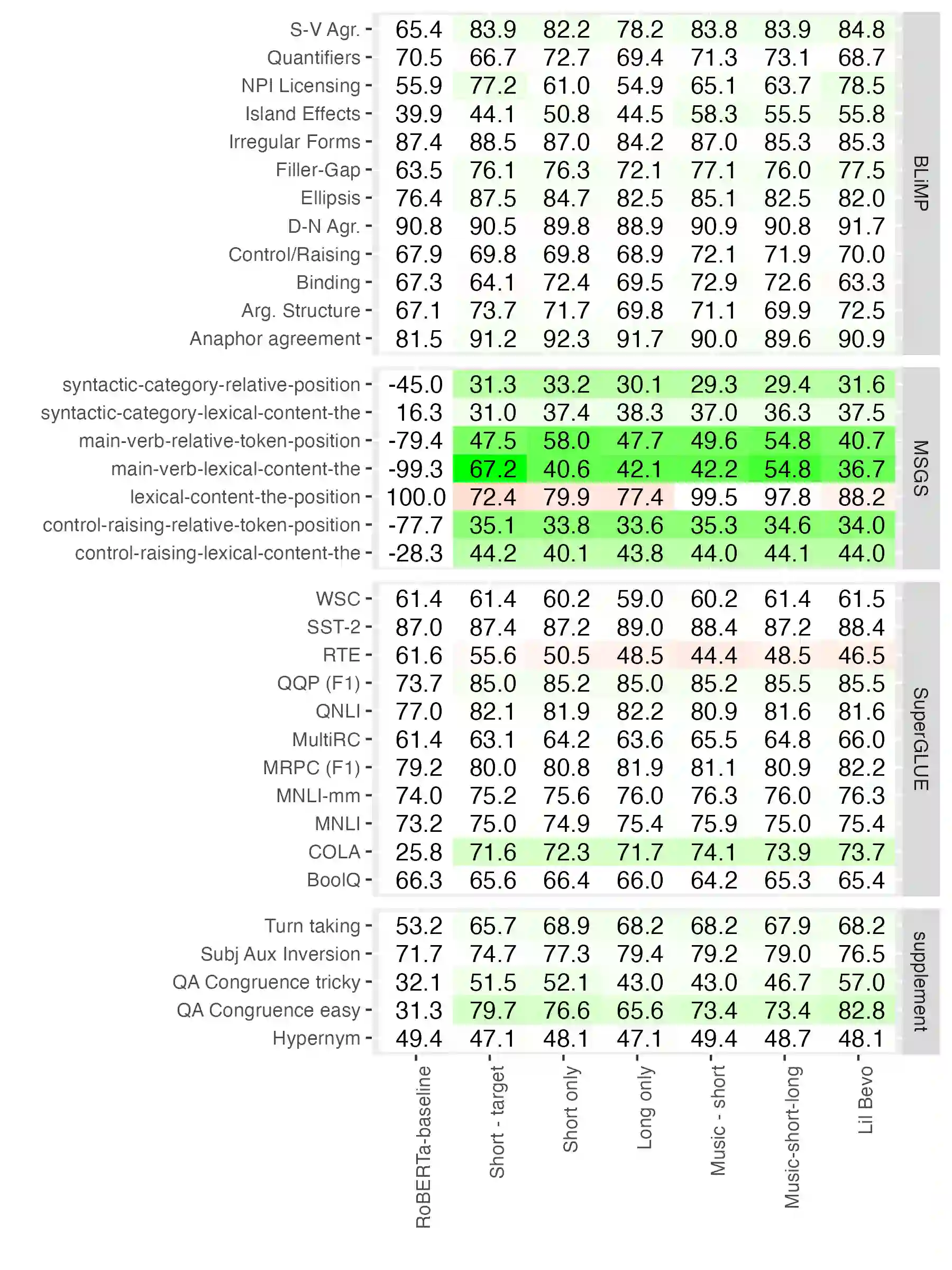
We present Lil-Bevo, our submission to the BabyLM Challenge. We pretrained our masked language models with three ingredients: an initial pretraining with music data, training on shorter sequences before training on longer ones, and masking specific tokens to target some of the BLiMP subtasks. Overall, our baseline models performed above chance, but far below the performance levels of larger LLMs trained on more data. We found that training on short sequences performed better than training on longer sequences.Pretraining on music may help performance marginally, but, if so, the effect seems small. Our targeted Masked Language Modeling augmentation did not seem to improve model performance in general, but did seem to help on some of the specific BLiMP tasks that we were targeting (e.g., Negative Polarity Items). Training performant LLMs on small amounts of data is a difficult but potentially informative task. While some of our techniques showed some promise, more work is needed to explore whether they can improve performance more than the modest gains here. Our code is available at https://github.com/venkatasg/Lil-Bevo and out models at https://huggingface.co/collections/venkatasg/babylm-653591cdb66f4bf68922873a
翻译:暂无翻译