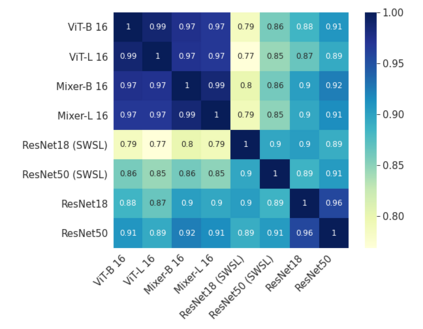
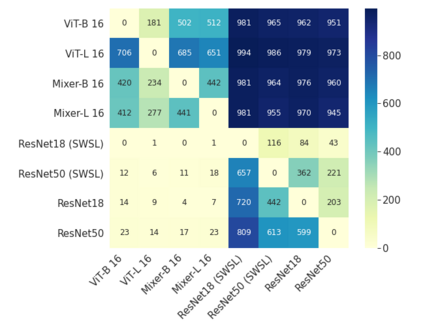
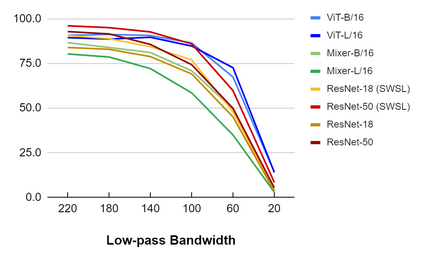
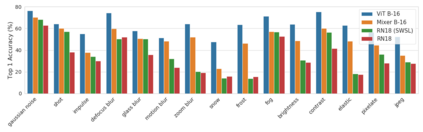
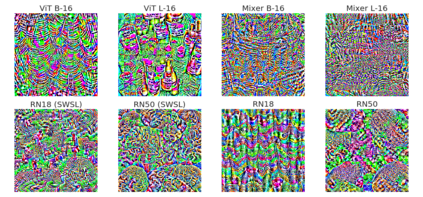
Convolutional Neural Networks (CNNs) have become the de facto gold standard in computer vision applications in the past years. Recently, however, new model architectures have been proposed challenging the status quo. The Vision Transformer (ViT) relies solely on attention modules, while the MLP-Mixer architecture substitutes the self-attention modules with Multi-Layer Perceptrons (MLPs). Despite their great success, CNNs have been widely known to be vulnerable to adversarial attacks, causing serious concerns for security-sensitive applications. Thus, it is critical for the community to know whether the newly proposed ViT and MLP-Mixer are also vulnerable to adversarial attacks. To this end, we empirically evaluate their adversarial robustness under several adversarial attack setups and benchmark them against the widely used CNNs. Overall, we find that the two architectures, especially ViT, are more robust than their CNN models. Using a toy example, we also provide empirical evidence that the lower adversarial robustness of CNNs can be partially attributed to their shift-invariant property. Our frequency analysis suggests that the most robust ViT architectures tend to rely more on low-frequency features compared with CNNs. Additionally, we have an intriguing finding that MLP-Mixer is extremely vulnerable to universal adversarial perturbations.
翻译:过去几年来,有线电视网已成为计算机视觉应用中事实上的黄金标准。然而,最近,提出了新的模型架构,对现状提出了挑战。展望变异器(VIT)完全依赖关注模块,而MLP-混合器架构则用多功能感应器(MLPs)取代自我关注模块。尽管取得了巨大成功,但众所周知CNN很容易受到对抗性攻击,从而引起对安全敏感的应用程序的严重关切。因此,社区必须了解新提议的VIT和MLP-Mixer是否也容易受到对抗性攻击。为此,我们从经验上评估了它们在若干对抗性攻击装置下的对抗性强势性强势,并根据广泛使用的CNNs进行基准。总体而言,我们发现这两个架构,特别是ViT,比CNN模式更加强大。我们还提供了实证证据表明,CNN的对抗性强的强势强势性强能部分可归因于它们的变化性属性。我们的频率分析表明,最强的MDRVI模型与最强的VIFIFI结构相比,往往要依赖最强的VIFIFI-VI。