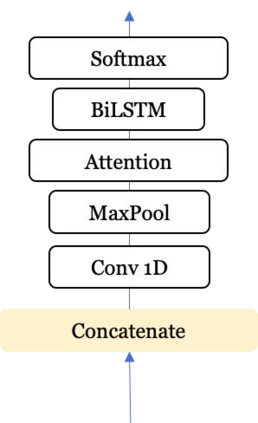
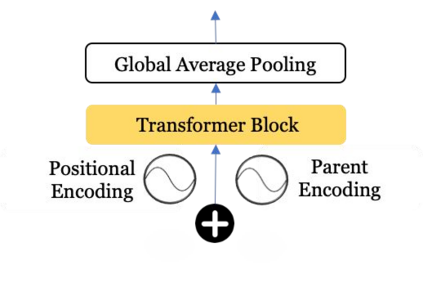
The conceptualization of a claim lies at the core of argument mining. The segregation of claims is complex, owing to the divergence in textual syntax and context across different distributions. Another pressing issue is the unavailability of labeled unstructured text for experimentation. In this paper, we propose LESA, a framework which aims at advancing headfirst into expunging the former issue by assembling a source-independent generalized model that captures syntactic features through part-of-speech and dependency embeddings, as well as contextual features through a fine-tuned language model. We resolve the latter issue by annotating a Twitter dataset which aims at providing a testing ground on a large unstructured dataset. Experimental results show that LESA improves upon the state-of-the-art performance across six benchmark claim datasets by an average of 3 claim-F1 points for in-domain experiments and by 2 claim-F1 points for general-domain experiments. On our dataset too, LESA outperforms existing baselines by 1 claim-F1 point on the in-domain experiments and 2 claim-F1 points on the general-domain experiments. We also release comprehensive data annotation guidelines compiled during the annotation phase (which was missing in the current literature).
翻译:主张的概念化是论据挖掘的核心。由于不同分布的文字语法和背景存在差异,索赔的分类十分复杂。另一个紧迫的问题是没有标签的无结构化实验文本。在本文中,我们提出LESA,这是一个框架,旨在通过收集一个独立源的通用模型,通过部分语音和依赖嵌入和依赖嵌入,以及通过一个微调的语言模型来捕捉合成特征,以及背景特征,从而将索赔的概念分割为复杂。我们通过一个Twitter数据集来解决后一个问题,该数据集的目的是在大型非结构化数据集上提供一个测试场。实验结果显示,LESA在六个基准索赔数据组中提高了最新性能,平均3个索赔-F1点用于现场实验,2个索赔-F1点用于普通实验。关于我们的数据集,LESA在内部实验中比现有基线高出1个索赔-F1点,而在目前综合实验中,我们所汇编了1个索赔-F1号指南,在目前全面实验阶段中,我们又汇编了1个数据单元。