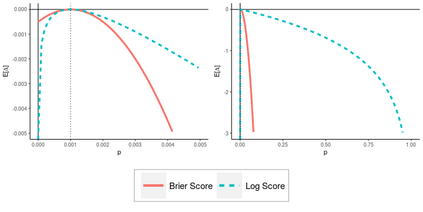
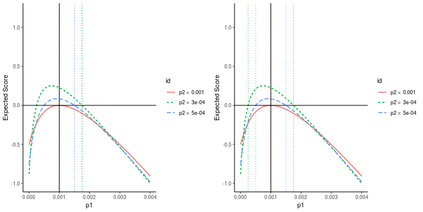
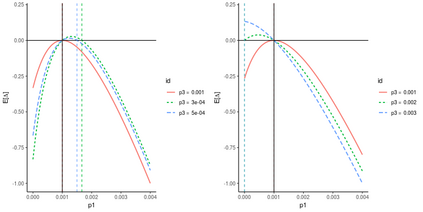
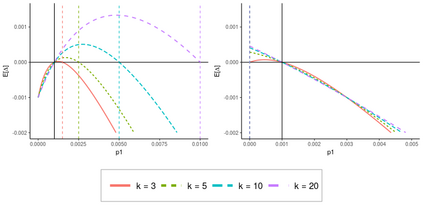
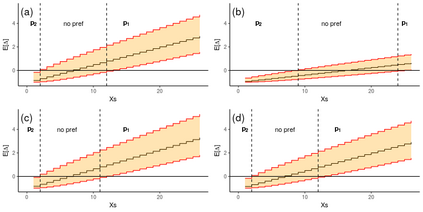
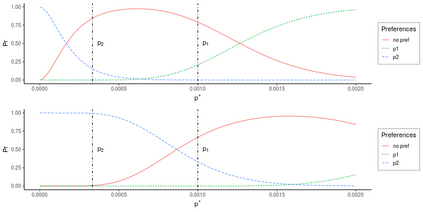
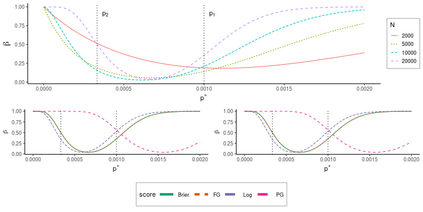
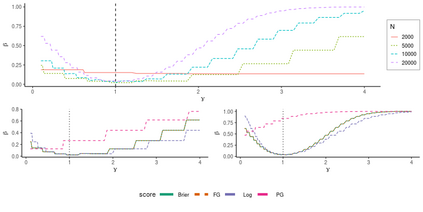
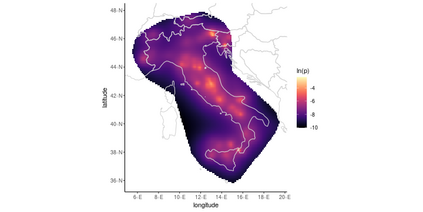
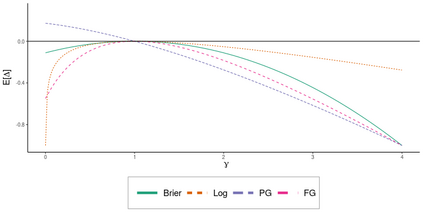
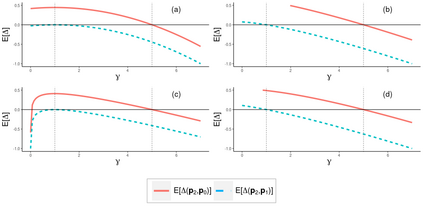
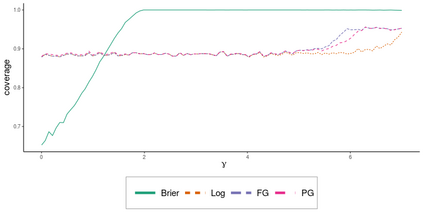
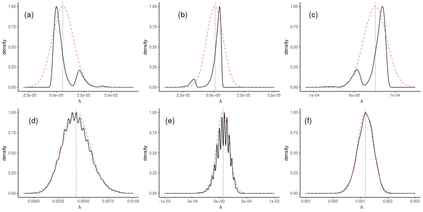
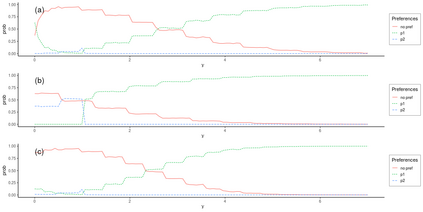
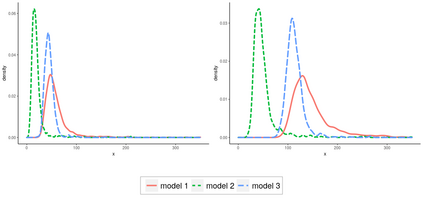
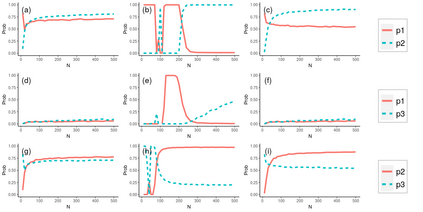
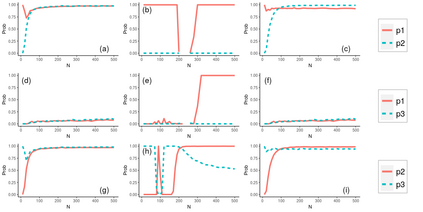
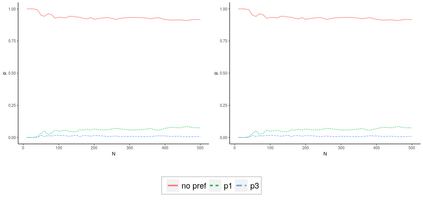
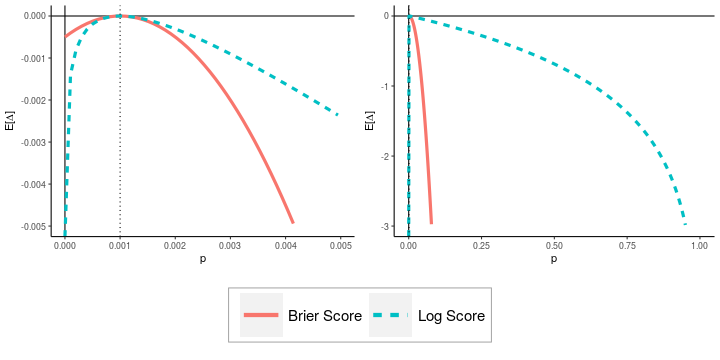
Operational earthquake forecasting for risk management and communication during seismic sequences depends on our ability to select an optimal forecasting model. To do this, we need to compare the performance of competing models with each other in prospective forecasting mode, and to rank their performance using a fair, reproducible and reliable method. The Collaboratory for the Study of Earthquake Predictability (CSEP) conducts such prospective earthquake forecasting experiments around the globe. One metric that has been proposed to rank competing models is the Parimutuel Gambling score, which has the advantage of allowing alarm-based (categorical) forecasts to be compared with probabilistic ones. Here we examine the suitability of this score for ranking competing earthquake forecasts. First, we prove analytically that this score is in general improper, meaning that, on average, it does not prefer the model that generated the data. Even in the special case where it is proper, we show it can still be used in an improper way. Then, we compare its performance with two commonly-used proper scores (the Brier and logarithmic scores), taking into account the uncertainty around the observed average score. We estimate the confidence intervals for the expected score difference which allows us to define if and when a model can be preferred. We extend the analysis to show how much data are required, in principle, for a test to express a preference towards a particular forecast. Such thresholds could be used in experimental design to specify the duration, time windows, and spatial discretisation of earthquake models and forecasts. Our findings suggest the Parimutuel Gambling score should not be used to distinguishing between multiple competing forecasts. They also enable a more rigorous approach to distinguish between the predictive skills of candidate forecasts in addition to their rankings.
翻译:在地震序列中进行风险管理和通信的业务地震预测取决于我们选择最佳预测模型的能力。 为了做到这一点,我们需要在预测预测模式中比较相互竞争模型的性能,并使用公平、可复制和可靠的方法对模型的性能进行排名。 地震可预测性研究协作机构(CESP)在全球进行此类潜在地震预测实验。 提议用来对竞争性模型进行排名的一个衡量标准是Parimutuel赌博分,它的好处是允许以警报为基础的(分类)预测与概率性预测进行比较。 我们在这里检查这一评分是否适合对相竞争的地震预测进行排序。 首先,我们从分析上证明,这一评分总体上是不适当的,这意味着平均而言,它并不倾向于生成数据的模型。 即使在特别情况下,我们仍可以以不适当的方式使用该标准。 然后,我们将其业绩与两种常用的适当得分(Brier 和logialthrical ) 比较, 以考虑到所观察到的平均得分的不确定性。 我们估计这一得分的比是否合适。 我们估计了这一评分的比值, 平均的比值通常用来用来测定的比值应该用来测定我们所估计的比值的比值值, 用来用来测量的比值的数值,如果我们所使用的数值可以用来用来用来用来测定的比值,那么的比值是用来用来计算。