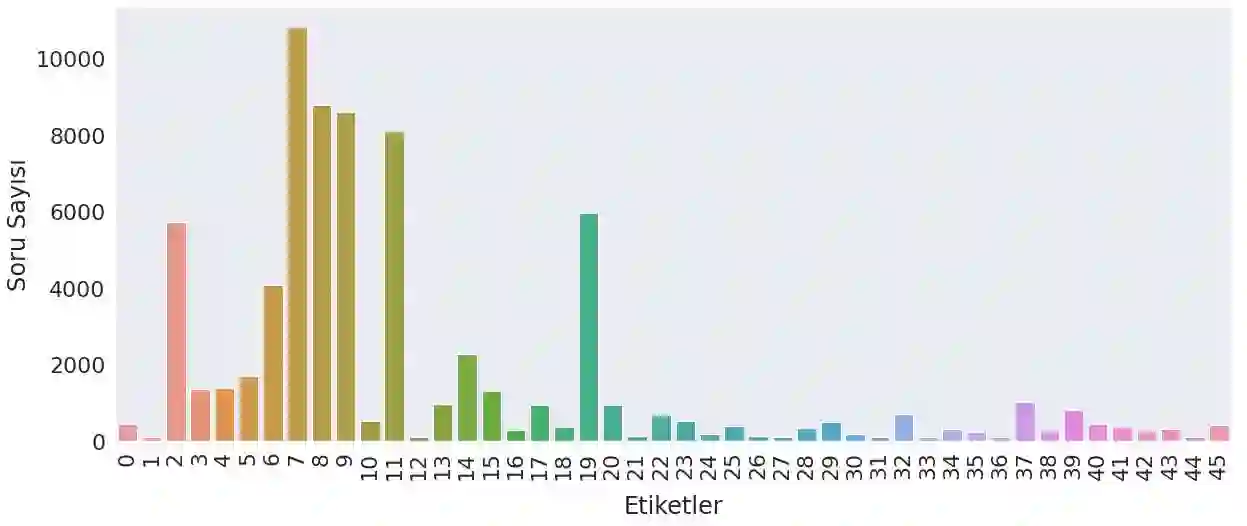
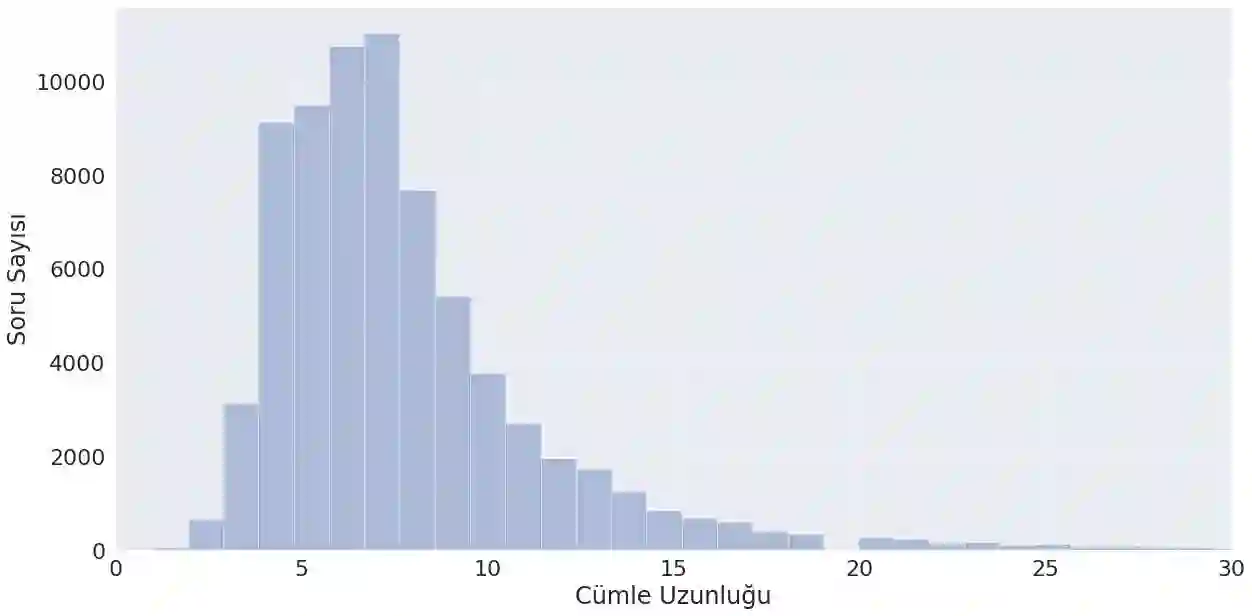
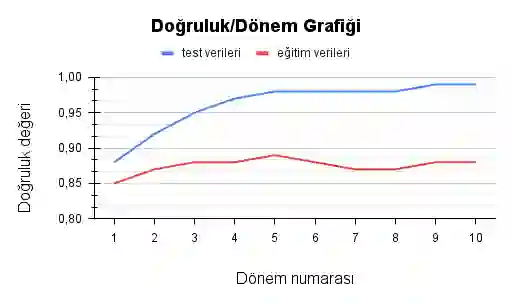
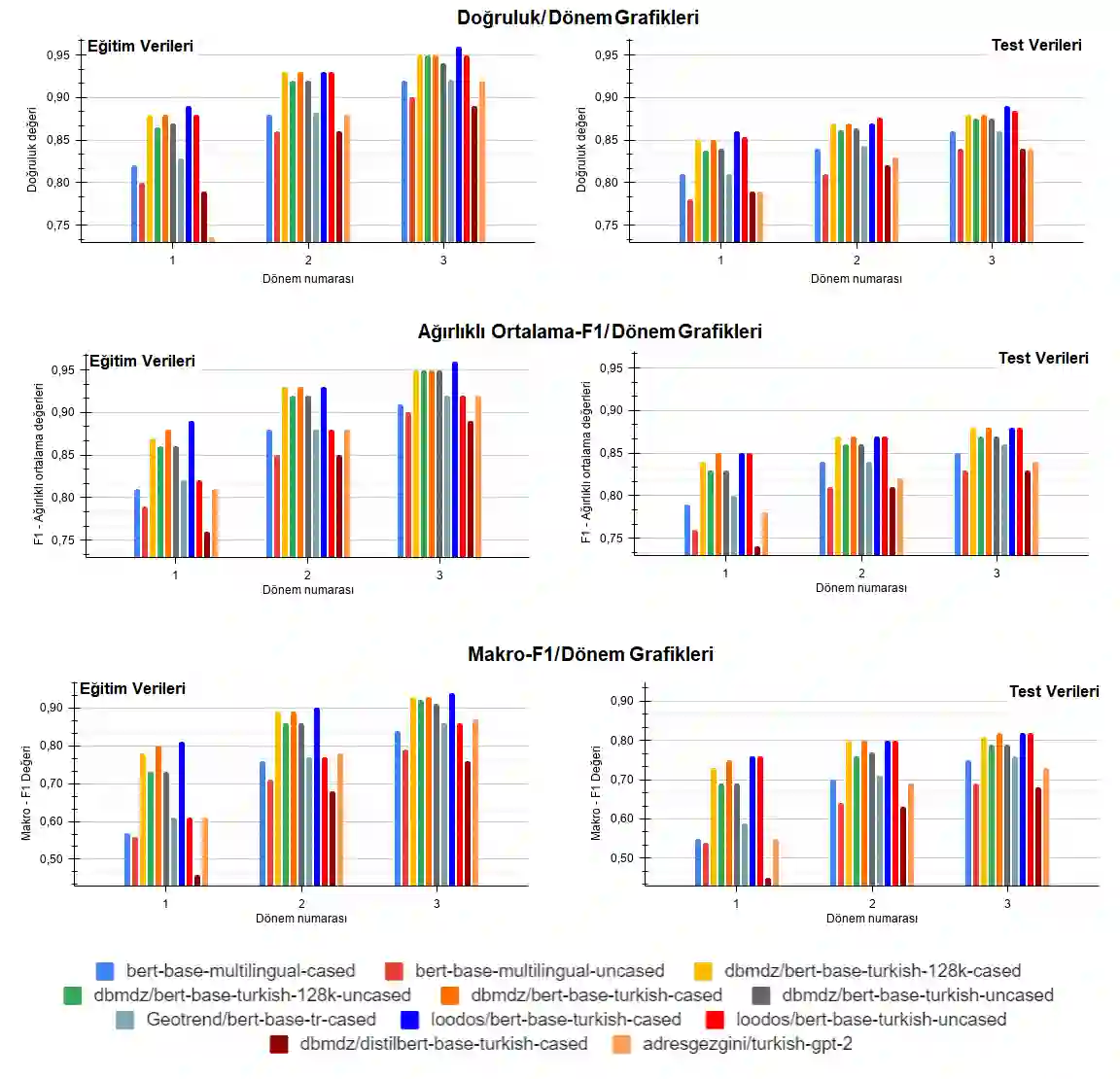
The problem of categorizing short speech sentences according to their semantic features with high accuracy is a subject studied in natural language processing. In this study, a data set created with samples classified in 46 different categories was used. Examples consist of sentences taken from chat conversations between a company's customer representatives and the company's website visitors. The primary purpose is to automatically tag questions and requests from visitors in the most accurate way for 46 predetermined categories for use in a chat application to generate meaningful answers to the questions asked by the website visitors. For this, different BERT models and one GPT-2 model, pre-trained in Turkish, were preferred. The classification performances of the relevant models were analyzed in detail and reported accordingly.
翻译:在自然语言处理过程中研究的一个课题是按照语义特征对短话进行精准分类的问题,在这项研究中,采用了按46个不同类别分类的样本制作的数据集,例如,公司客户代表和公司网站访问者之间的聊天交谈中作出的判决,主要目的是用最准确的方式自动标记访问者的问题和要求,46个预先确定的类别,以便用于聊天应用程序,对网站访问者提出的问题作出有意义的答复,为此,选择了不同的BERT模型和一个土耳其语预先培训的GPT-2模型,对有关模型的分类表现进行了详细分析,并据此作了报告。