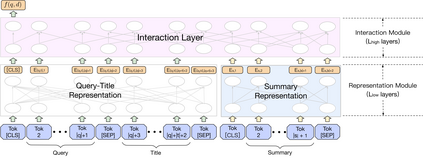
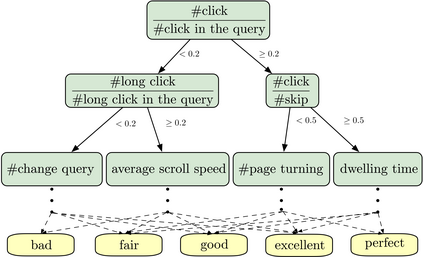
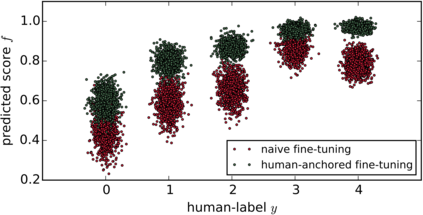
As the heart of a search engine, the ranking system plays a crucial role in satisfying users' information demands. More recently, neural rankers fine-tuned from pre-trained language models (PLMs) establish state-of-the-art ranking effectiveness. However, it is nontrivial to directly apply these PLM-based rankers to the large-scale web search system due to the following challenging issues:(1) the prohibitively expensive computations of massive neural PLMs, especially for long texts in the web-document, prohibit their deployments in an online ranking system that demands extremely low latency;(2) the discrepancy between existing ranking-agnostic pre-training objectives and the ad-hoc retrieval scenarios that demand comprehensive relevance modeling is another main barrier for improving the online ranking system;(3) a real-world search engine typically involves a committee of ranking components, and thus the compatibility of the individually fine-tuned ranking model is critical for a cooperative ranking system. In this work, we contribute a series of successfully applied techniques in tackling these exposed issues when deploying the state-of-the-art Chinese pre-trained language model, i.e., ERNIE, in the online search engine system. We first articulate a novel practice to cost-efficiently summarize the web document and contextualize the resultant summary content with the query using a cheap yet powerful Pyramid-ERNIE architecture. Then we endow an innovative paradigm to finely exploit the large-scale noisy and biased post-click behavioral data for relevance-oriented pre-training. We also propose a human-anchored fine-tuning strategy tailored for the online ranking system, aiming to stabilize the ranking signals across various online components. Extensive offline and online experimental results show that the proposed techniques significantly boost the search engine's performance.
翻译:作为搜索引擎的核心,排名系统在满足用户信息需求方面发挥着关键作用。最近,神经定级器根据预先培训的语文模型(PLM)对神经定级器进行微调,建立了最先进的排名效果。然而,由于以下具有挑战性的问题,直接将这些基于PLM的定级器应用到大型网络搜索系统是非技术性的:(1) 大规模神经人文(特别是网络文件中的长文本)的计算过于昂贵,禁止将其部署在网上定级系统中,这需要极低的延缓;(2) 现有的定级推进培训前目标与需要全面相关性模型的自动检索方案之间的差异,是改进在线定级系统的另一个主要障碍;(3) 现实世界搜索引擎通常包含一个排名委员会,因此,个人精确的定级模型的兼容性对于合作性排名系统至关重要。 在部署中国国家预培训前语言模型时,我们提出一系列成功应用的技术来解决这些暴露的问题, 在线定级前语言模型(i.e.,ERNIE) 和自动检索假设性战略之间的差异性模型是改进在线定级模型, 并且在线将在线上一个高额的流程的流程显示一个在线结果。