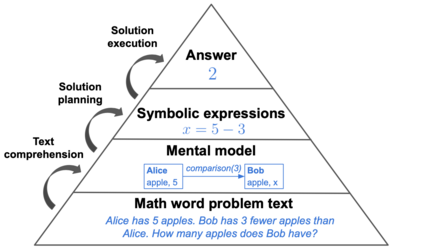
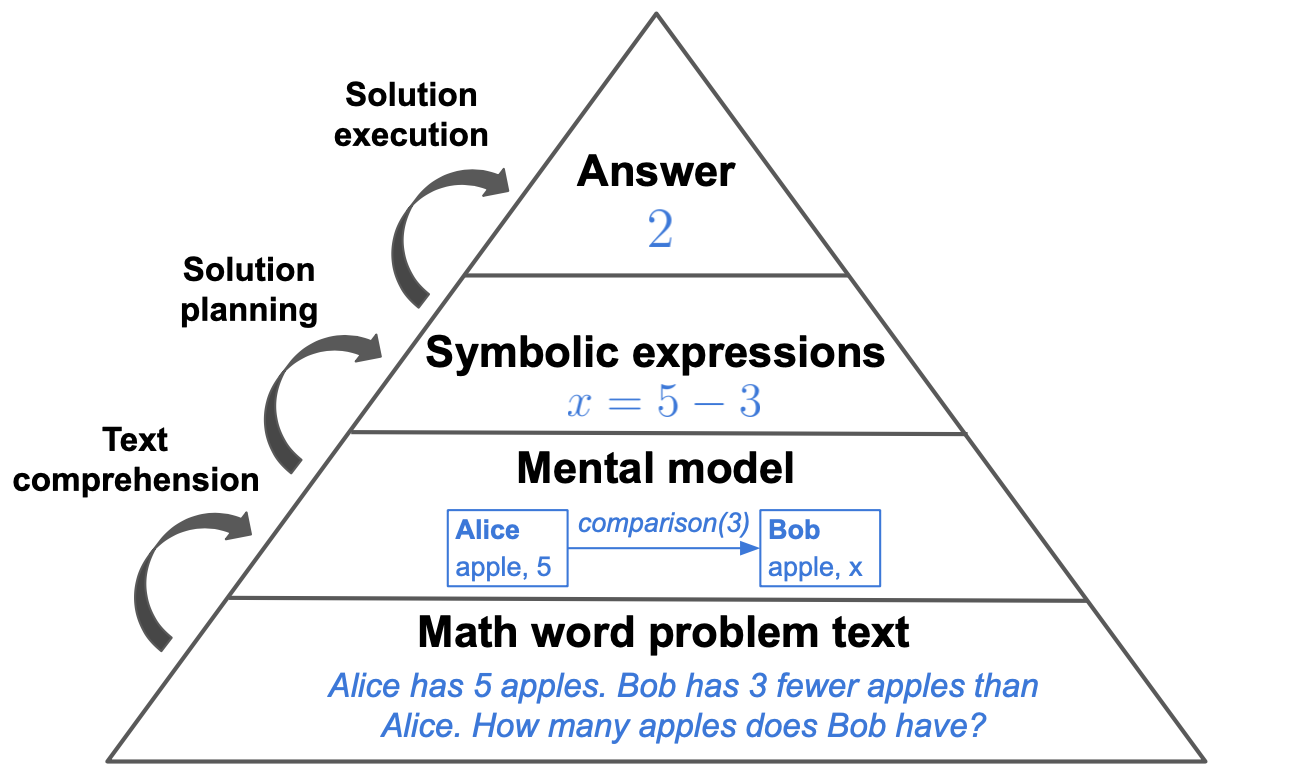
There is increasing interest in employing large language models (LLMs) as cognitive models. For such purposes, it is central to understand which cognitive properties are well-modeled by LLMs, and which are not. In this work, we study the biases of LLMs in relation to those known in children when solving arithmetic word problems. Surveying the learning science literature, we posit that the problem-solving process can be split into three distinct steps: text comprehension, solution planning and solution execution. We construct tests for each one in order to understand which parts of this process can be faithfully modeled by current state-of-the-art LLMs. We generate a novel set of word problems for each of these tests, using a neuro-symbolic method that enables fine-grained control over the problem features. We find evidence that LLMs, with and without instruction-tuning, exhibit human-like biases in both the text-comprehension and the solution-planning steps of the solving process, but not during the final step which relies on the problem's arithmetic expressions (solution execution).
翻译:暂无翻译