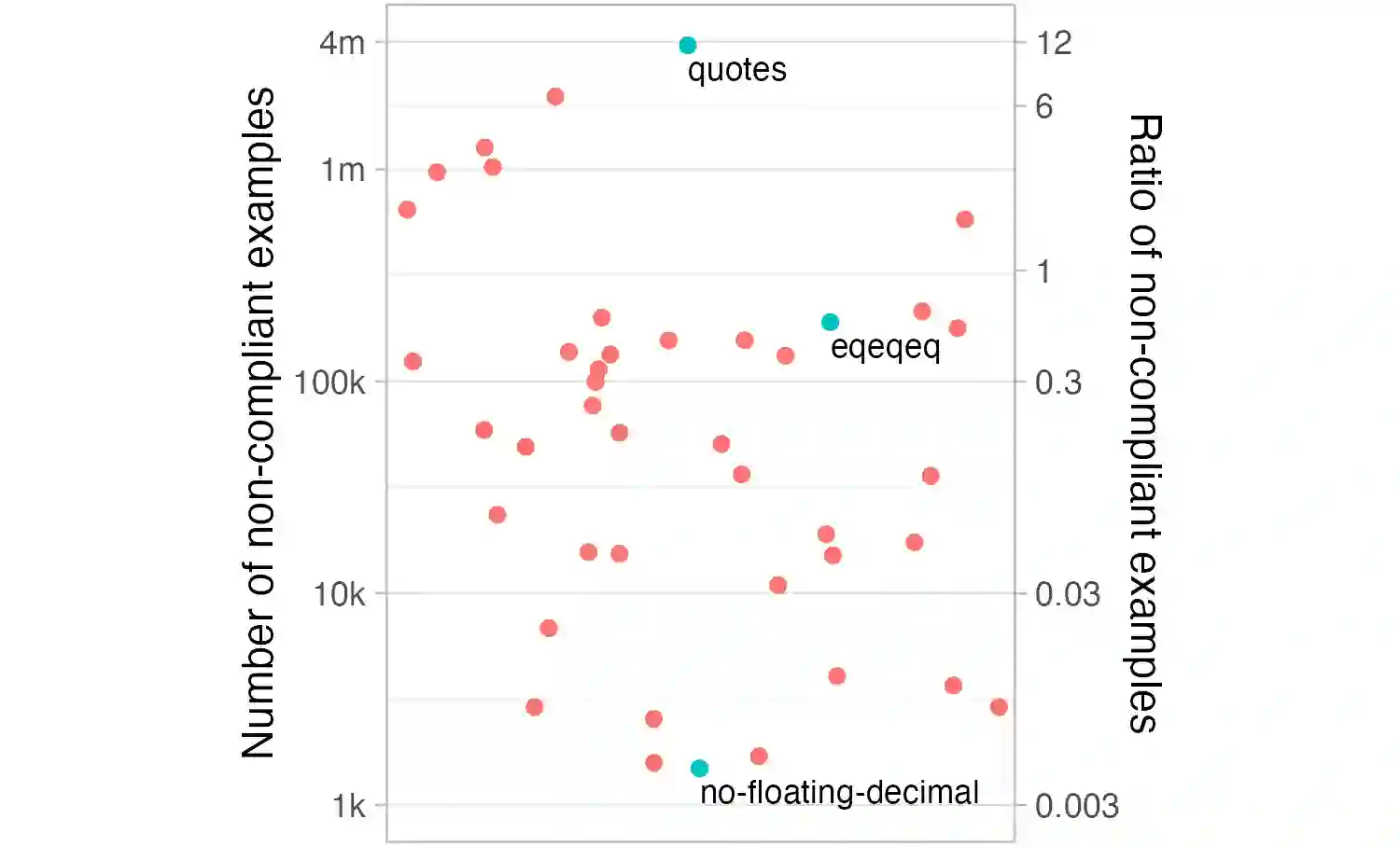
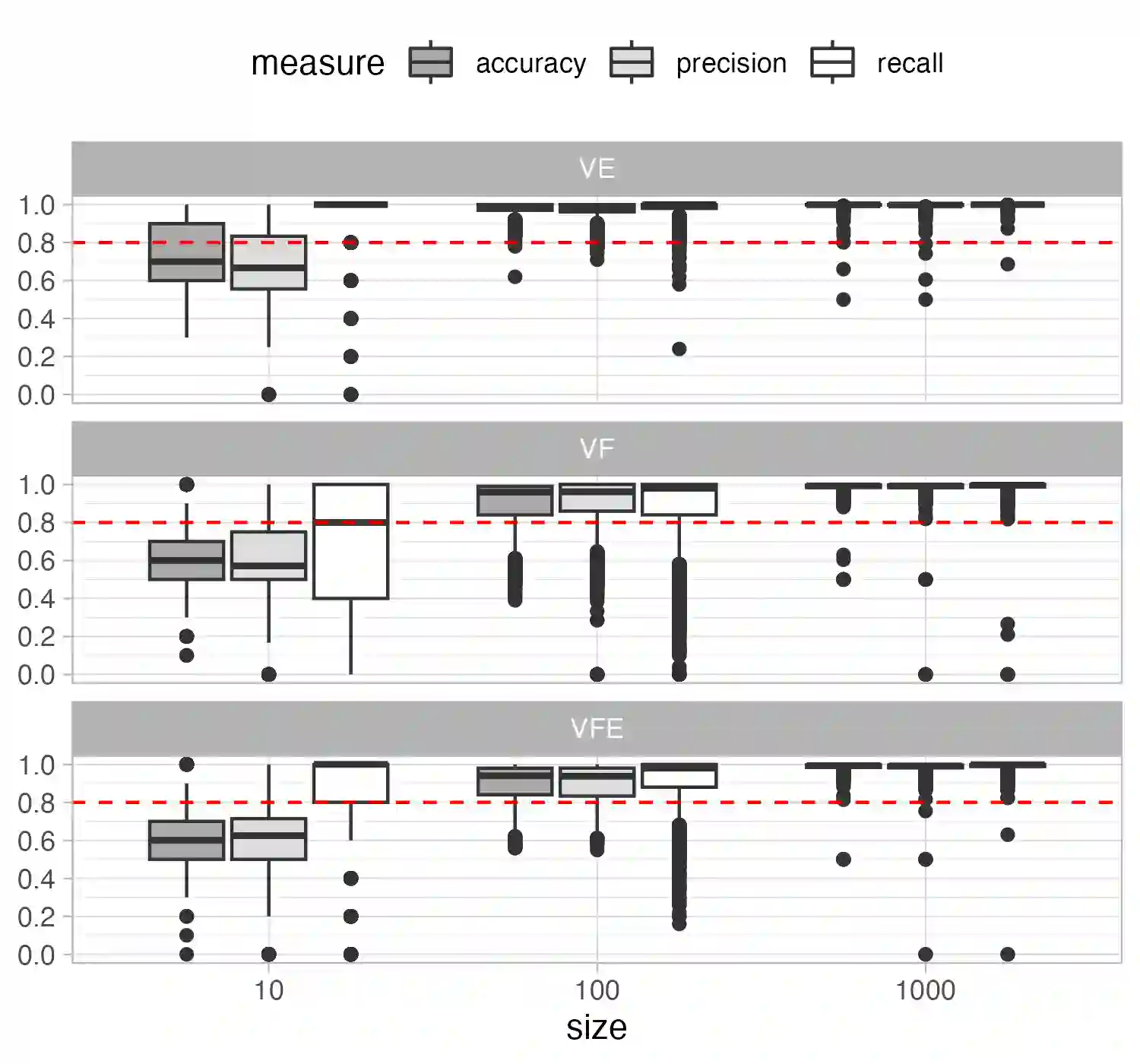
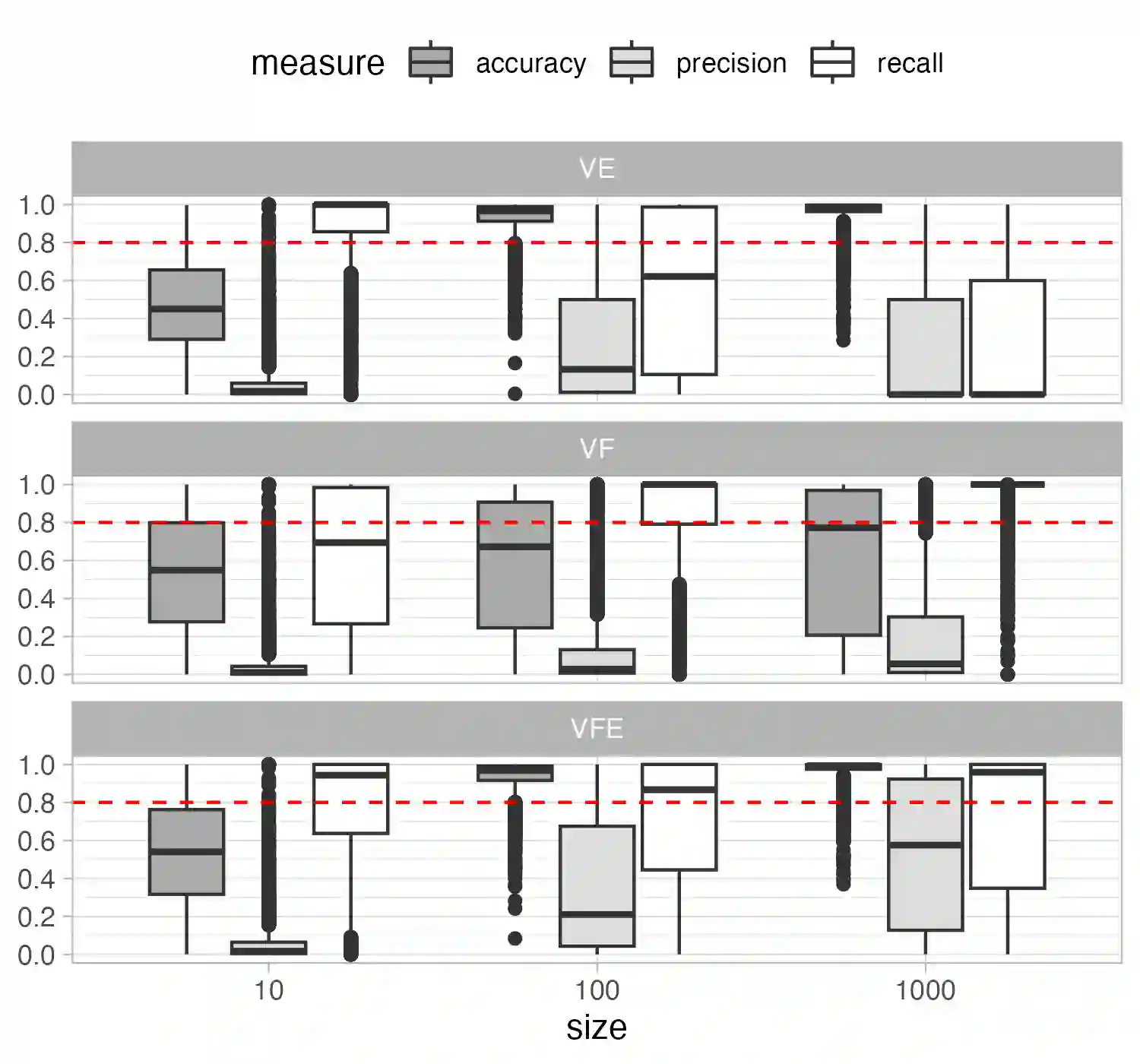
Coding practices are increasingly used by software companies. Their use promotes consistency, readability, and maintainability, which contribute to software quality. Coding practices were initially enforced by general-purpose linters, but companies now tend to design and adopt their own company-specific practices. However, these company-specific practices are often not automated, making it challenging to ensure they are shared and used by developers. Converting these practices into linter rules is a complex task that requires extensive static analysis and language engineering expertise. In this paper, we seek to answer the following question: can coding practices be learned automatically from examples manually tagged by developers? We conduct a feasibility study using CodeBERT, a state-of-the-art machine learning approach, to learn linter rules. Our results show that, although the resulting classifiers reach high precision and recall scores when evaluated on balanced synthetic datasets, their application on real-world, unbalanced codebases, while maintaining excellent recall, suffers from a severe drop in precision that hinders their usability.
翻译:软件公司越来越多地采用编码做法,使用这些做法可以促进一致性、可读性和可维护性,从而有助于软件质量。编码做法最初由通用的Linters实施,但公司现在倾向于设计和采用自己的公司特定做法。然而,这些具体公司的做法往往不是自动化的,因此难以确保开发商分享和使用这些做法。将这些做法转换成Linter规则是一项复杂的任务,需要广泛的静态分析和语言工程专业知识。在本文件中,我们试图回答以下问题:从开发商手工标注的例子中自动学习编码做法可以自动吗?我们用一个最先进的机器学习方法(codeBERT)进行可行性研究,以学习Linter规则。我们的结果显示,尽管由此产生的分类者在评价平衡的合成数据集时达到很高的精确度和回顾得分数,但在实际世界应用时,它们不平衡的代码库虽然保持良好的回顾,但因精确度严重下降而妨碍其可用性。