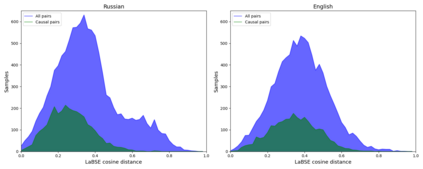
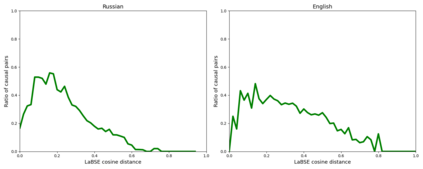
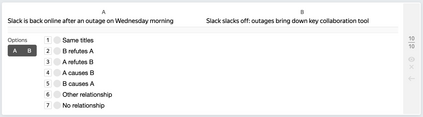
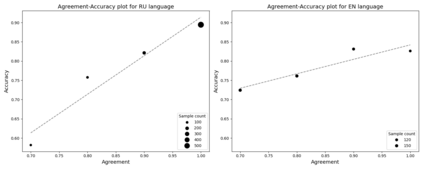
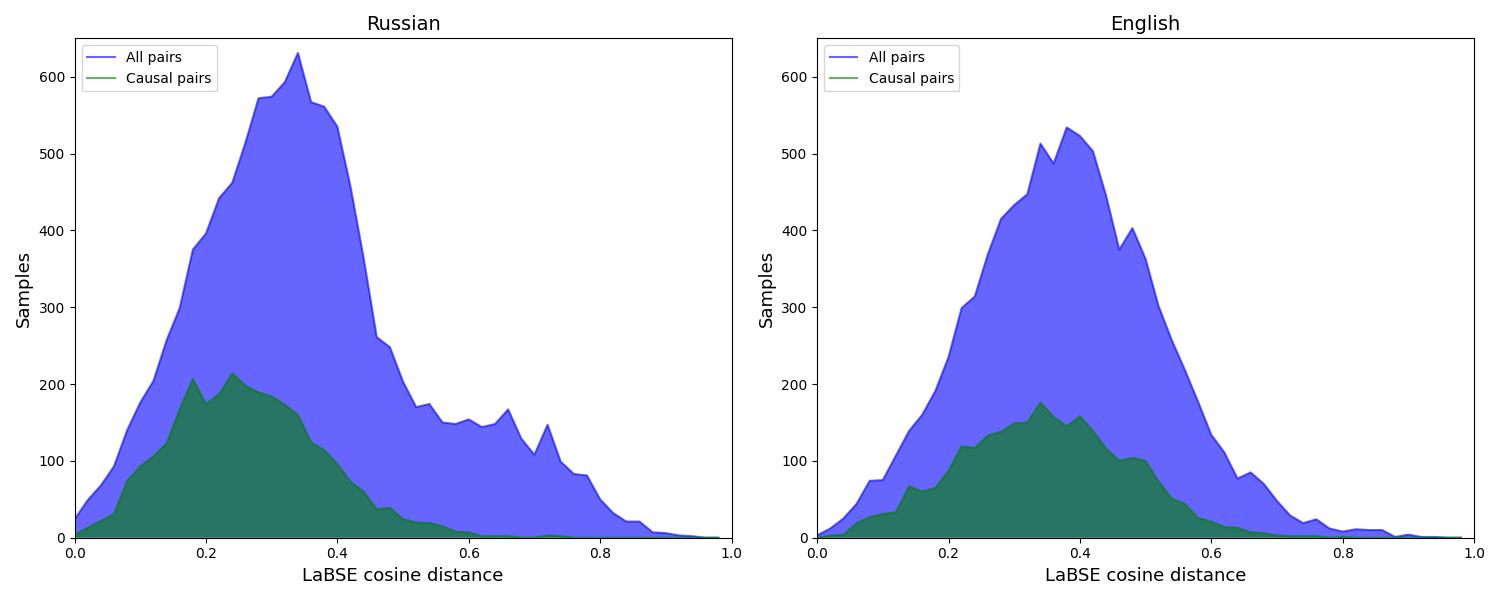
Detecting implicit causal relations in texts is a task that requires both common sense and world knowledge. Existing datasets are focused either on commonsense causal reasoning or explicit causal relations. In this work, we present HeadlineCause, a dataset for detecting implicit causal relations between pairs of news headlines. The dataset includes over 5000 headline pairs from English news and over 9000 headline pairs from Russian news labeled through crowdsourcing. The pairs vary from totally unrelated or belonging to the same general topic to the ones including causation and refutation relations. We also present a set of models and experiments that demonstrates the dataset validity, including a multilingual XLM-RoBERTa based model for causality detection and a GPT-2 based model for possible effects prediction.
翻译:检测文本中的隐含因果关系是一项需要常识和世界知识的任务。现有的数据集要么侧重于常识因果推理,要么侧重于明显的因果关系。在这项工作中,我们展示了标题“因果关系 ”, 这是用于检测新闻头条新闻之间隐含因果关系的数据集。数据集包括来自英国新闻的5 000多条头条新闻和来自俄罗斯新闻的9 000多条头条新闻,通过众包标注。这些对子从完全不相干或属于同一一般专题,到包括因果关系和反驳关系。我们还展示了一组模型和实验,以证明数据集的有效性,包括基于多语言的因果性检测XLM-ROBERTA模型和基于GPT-2的可能效果预测模型。