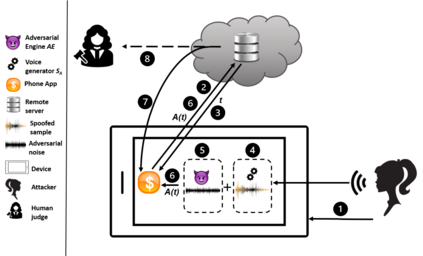
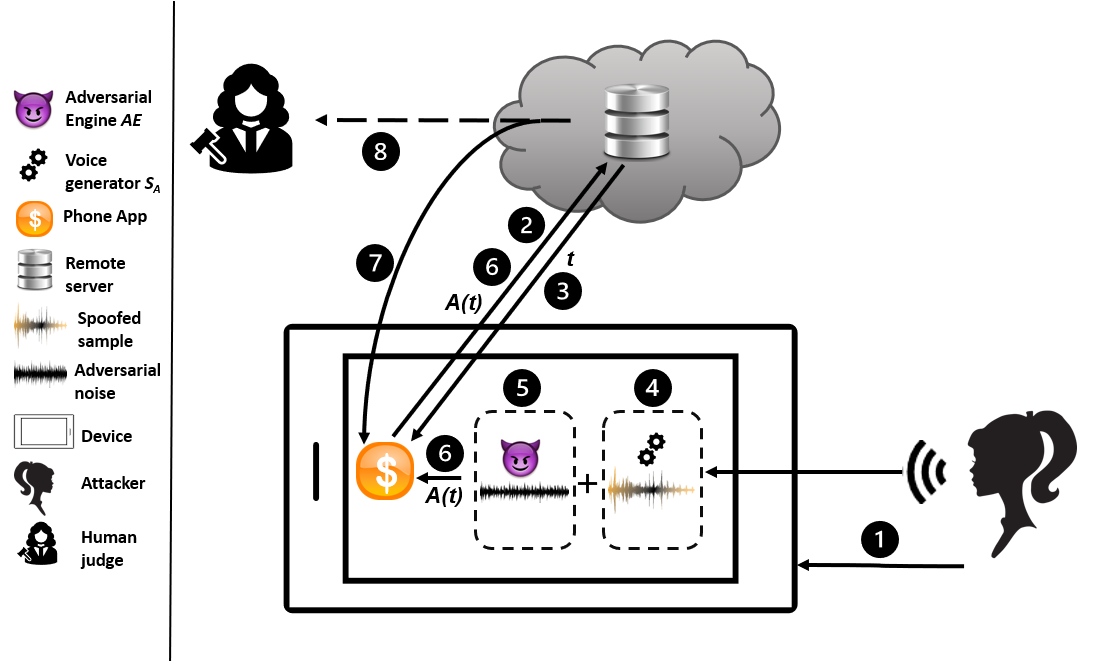
Voice authentication has become an integral part in security-critical operations, such as bank transactions and call center conversations. The vulnerability of automatic speaker verification systems (ASVs) to spoofing attacks instigated the development of countermeasures (CMs), whose task is to tell apart bonafide and spoofed speech. Together, ASVs and CMs form today's voice authentication platforms, advertised as an impregnable access control mechanism. We develop the first practical attack on CMs, and show how a malicious actor may efficiently craft audio samples to bypass voice authentication in its strictest form. Previous works have primarily focused on non-proactive attacks or adversarial strategies against ASVs that do not produce speech in the victim's voice. The repercussions of our attacks are far more severe, as the samples we generate sound like the victim, eliminating any chance of plausible deniability. Moreover, the few existing adversarial attacks against CMs mistakenly optimize spoofed speech in the feature space and do not take into account the existence of ASVs, resulting in inferior synthetic audio that fails in realistic settings. We eliminate these obstacles through our key technical contribution: a novel joint loss function that enables mounting advanced adversarial attacks against combined ASV/CM deployments directly in the time domain. Our adversarials achieve concerning black-box success rates against state-of-the-art authentication platforms (up to 93.57\%). Finally, we perform the first targeted, over-telephony-network attack on CMs, bypassing several challenges and enabling various potential threats, given the increased use of voice biometrics in call centers. Our results call into question the security of modern voice authentication systems in light of the real threat of attackers bypassing these measures to gain access to users' most valuable resources.
翻译:自动扬声器核查系统(ASVs)容易被攻击,而这种攻击不会在受害者的声音中产生言论。我们的攻击影响要严重得多,因为我们制作的样本听起来像受害者一样,消除了任何可能的贬低机会。此外,目前对CMs的对抗性攻击很少,在地貌空间里,我们错误地优化了对声波的言论,没有考虑到ASSV的呼声,导致在现实环境中出现低劣的合成音频。我们消除了这些障碍,我们通过核心的亚马逊式攻击,我们增加了对亚马逊式攻击的潜在成本。