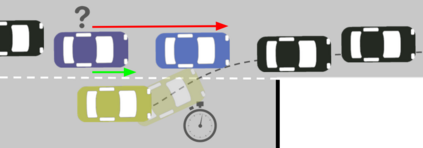
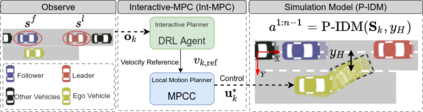
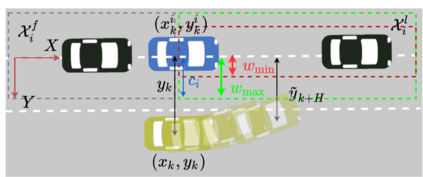
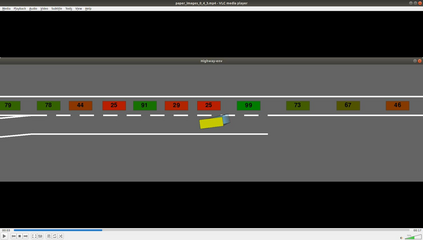
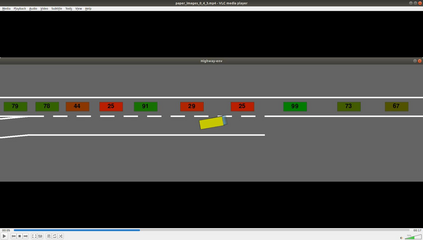
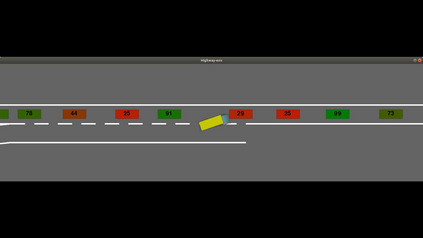
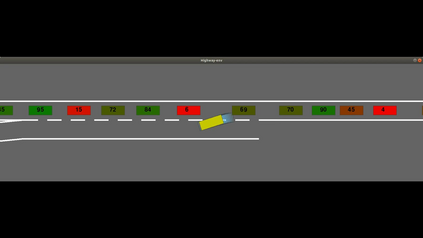
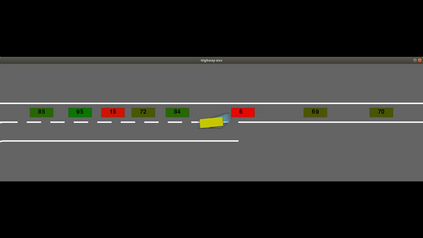
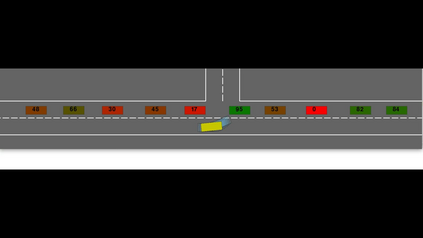
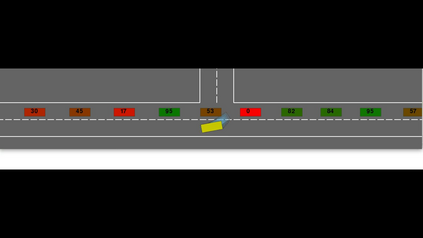
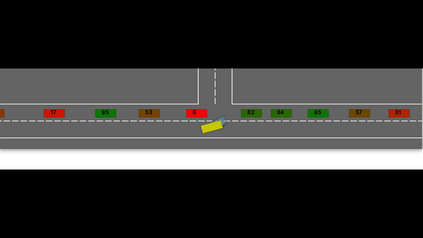
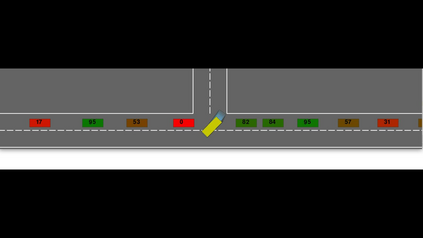
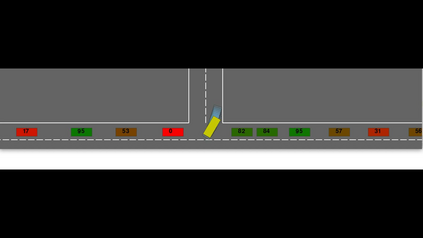
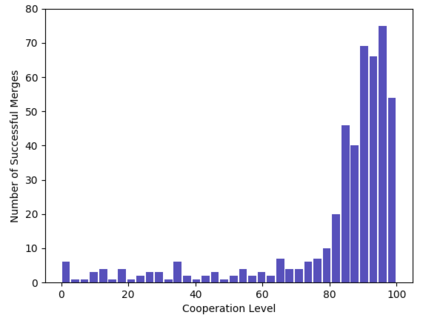
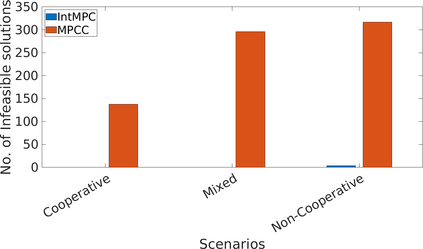
Autonomous navigation in dense traffic scenarios remains challenging for autonomous vehicles (AVs) because the intentions of other drivers are not directly observable and AVs have to deal with a wide range of driving behaviors. To maneuver through dense traffic, AVs must be able to reason how their actions affect others (interaction model) and exploit this reasoning to navigate through dense traffic safely. This paper presents a novel framework for interaction-aware motion planning in dense traffic scenarios. We explore the connection between human driving behavior and their velocity changes when interacting. Hence, we propose to learn, via deep Reinforcement Learning (RL), an interaction-aware policy providing global guidance about the cooperativeness of other vehicles to an optimization-based planner ensuring safety and kinematic feasibility through constraint satisfaction. The learned policy can reason and guide the local optimization-based planner with interactive behavior to pro-actively merge in dense traffic while remaining safe in case the other vehicles do not yield. We present qualitative and quantitative results in highly interactive simulation environments (highway merging and unprotected left turns) against two baseline approaches, a learning-based and an optimization-based method. The presented results demonstrate that our method significantly reduces the number of collisions and increases the success rate with respect to both learning-based and optimization-based baselines.
翻译:由于其他驾驶员的意图不是直接可见的,而且AV必须处理广泛的驾驶行为。要通过密集的交通进行操控,AV必须能够解释其行动如何影响他人(互动模式),并利用这一推理安全地通过密集交通进行导航。本文为在密集交通情况下的互动意识运动规划提供了一个全新的框架。我们探讨了人驾驶行为与相互作用时速度变化之间的联系。因此,我们提议通过深强化学习(RL),学习一种互动意识政策,为其他车辆的合作提供全球指导,以优化为基础的规划员确保安全和动态可行性,通过约束性满意度。所学的政策可以解释和指导地方优化计划员与互动行为,以便主动合并密集交通,同时在其他车辆不产生效果的情况下保持安全。我们在高度互动的模拟环境中(高速度合并和无保护左转)展示质量和数量结果,以两种基线方法为基础,一种基于学习的和基于优化的方法,为全球提供指导,确保以优化为基础的计划员确保安全和动态可行性。所学的政策可以解释和指导地方优化计划员的基于互动行为,以便主动地将密集交通进行整合,同时保持安全。我们的方法在高度互动的模拟环境中(高速度合并和无保护左转),我们提出质和量模拟环境中提出质量和数量的结果,以学习为基础的模拟环境,以学习和优化方法将大大降低了学习率。