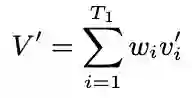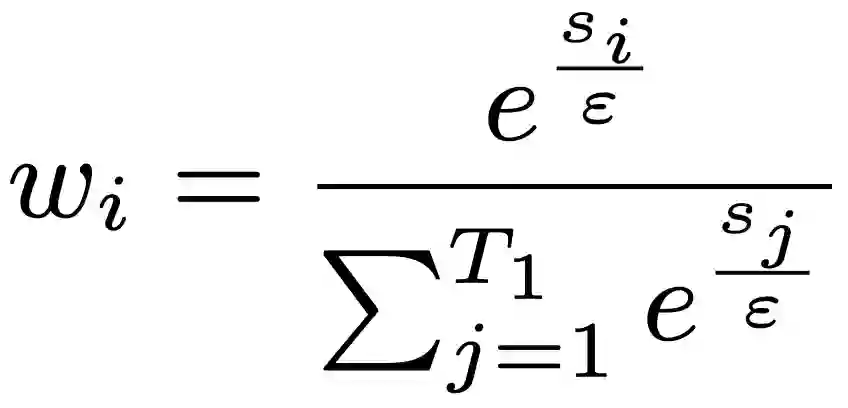Live commenting on video streams has surged in popularity on platforms like Twitch, enhancing viewer engagement through dynamic interactions. However, automatically generating contextually appropriate comments remains a challenging and exciting task. Video streams can contain a vast amount of data and extraneous content. Existing approaches tend to overlook an important aspect of prioritizing video frames that are most relevant to ongoing viewer interactions. This prioritization is crucial for producing contextually appropriate comments. To address this gap, we introduce a novel Semantic Frame Aggregation-based Transformer (SFAT) model for live video comment generation. This method not only leverages CLIP's visual-text multimodal knowledge to generate comments but also assigns weights to video frames based on their semantic relevance to ongoing viewer conversation. It employs an efficient weighted sum of frames technique to emphasize informative frames while focusing less on irrelevant ones. Finally, our comment decoder with a cross-attention mechanism that attends to each modality ensures that the generated comment reflects contextual cues from both chats and video. Furthermore, to address the limitations of existing datasets, which predominantly focus on Chinese-language content with limited video categories, we have constructed a large scale, diverse, multimodal English video comments dataset. Extracted from Twitch, this dataset covers 11 video categories, totaling 438 hours and 3.2 million comments. We demonstrate the effectiveness of our SFAT model by comparing it to existing methods for generating comments from live video and ongoing dialogue contexts.
翻译:在Twitch等平台上,直播视频流中的实时评论功能日益流行,通过动态互动增强了观众参与度。然而,自动生成上下文适宜的评论仍是一项具有挑战性且引人关注的任务。视频流可能包含大量数据及无关内容。现有方法往往忽视了一个重要方面:优先处理与当前观众互动最相关的视频帧。这种优先级划分对于生成上下文适宜的评论至关重要。为填补这一空白,我们提出了一种新颖的基于语义帧聚合的Transformer(SFAT)模型,用于直播视频评论生成。该方法不仅利用CLIP的视觉-文本多模态知识生成评论,还根据视频帧与当前观众对话的语义相关性为其分配权重。它采用高效的加权帧求和技术,以强调信息丰富的帧,同时减少对无关帧的关注。最后,我们的评论解码器采用跨注意力机制处理各模态,确保生成的评论能反映来自聊天和视频的上下文线索。此外,针对现有数据集主要集中于中文内容且视频类别有限的不足,我们构建了一个大规模、多样化、多模态的英文视频评论数据集。该数据集提取自Twitch,涵盖11个视频类别,总计438小时视频和320万条评论。通过将SFAT模型与现有方法在从直播视频和实时对话上下文生成评论方面进行比较,我们验证了其有效性。