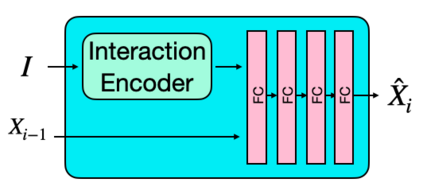
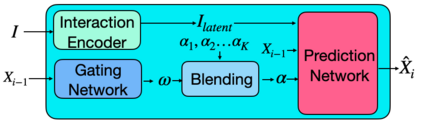
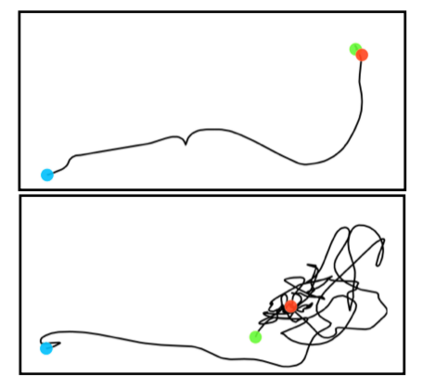
A long-standing goal in computer vision is to capture, model, and realistically synthesize human behavior. Specifically, by learning from data, our goal is to enable virtual humans to navigate within cluttered indoor scenes and naturally interact with objects. Such embodied behavior has applications in virtual reality, computer games, and robotics, while synthesized behavior can be used as a source of training data. This is challenging because real human motion is diverse and adapts to the scene. For example, a person can sit or lie on a sofa in many places and with varying styles. It is necessary to model this diversity when synthesizing virtual humans that realistically perform human-scene interactions. We present a novel data-driven, stochastic motion synthesis method that models different styles of performing a given action with a target object. Our method, called SAMP, for Scene-Aware Motion Prediction, generalizes to target objects of various geometries while enabling the character to navigate in cluttered scenes. To train our method, we collected MoCap data covering various sitting, lying down, walking, and running styles. We demonstrate our method on complex indoor scenes and achieve superior performance compared to existing solutions. Our code and data are available for research at https://samp.is.tue.mpg.de.
翻译:计算机愿景的长期目标是捕捉、 模型和现实合成人类行为。 具体地说, 我们的目标是通过从数据学习, 让虚拟人类能够在杂乱的室内环境里导航, 并自然地与物体互动。 这种体现的行为在虚拟现实、 计算机游戏和机器人中具有应用, 而合成的行为可以用作培训数据的来源。 这是因为真正的人类运动是多种多样的, 适应了场景。 例如, 一个人可以坐在或躺在沙发上, 并且有着不同的风格。 有必要将虚拟人类综合起来, 从而让虚拟人类在现实中进行人类- 银色互动。 我们展示一种由新颖的数据驱动的、 随机的动作合成方法, 用来模拟以目标对象为对象的动作。 我们的方法, 叫做 SAMP, 用于Sene- Awary Motion 预测, 概括了各种地理特征的目标, 同时又能让性能在杂乱的场景中行。 为了训练我们的方法, 我们收集了莫卡数据, 包括各种坐、 躺下、行走、 和运行着风格的虚拟人。 我们展示了我们现有的复杂图像和数据。 我们在室内的状态上可以使用的方法。 我们用的方法, 演示了我们的方法, 实现和高级的功能。