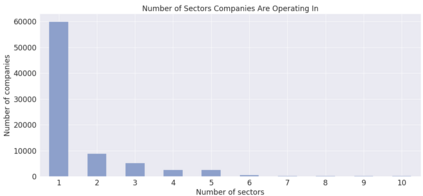
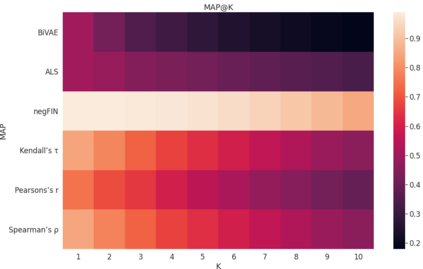
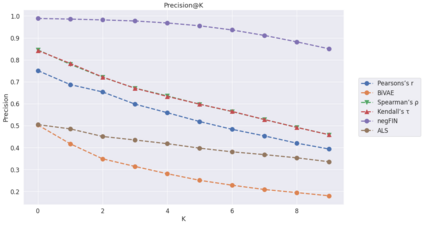
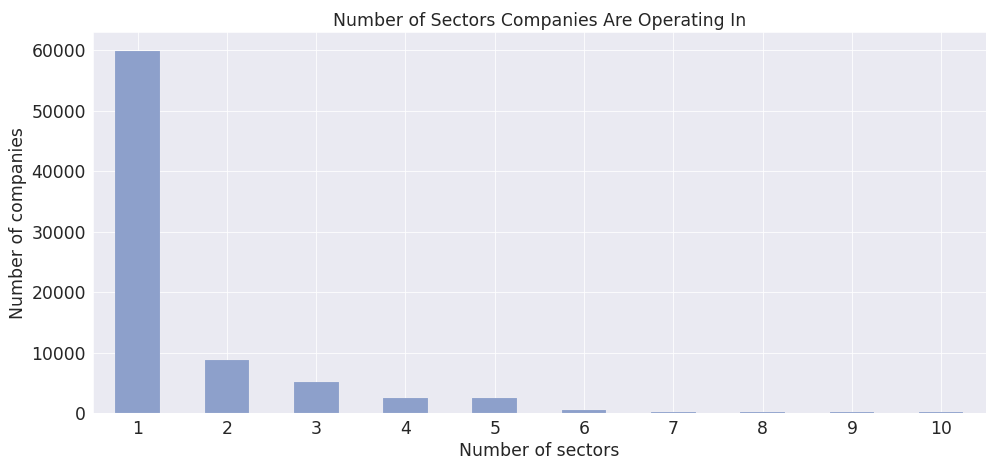
The term "sector" in professional business life is a vague concept since companies tend to identify themselves as operating in multiple sectors simultaneously. This ambiguity poses problems in recommending jobs to job seekers or finding suitable candidates for open positions. The latter holds significant importance when available candidates in a specific sector are also scarce; hence, finding candidates from similar sectors becomes crucial. This work focuses on discovering possible sector similarities through relational analysis. We employ several algorithms from the frequent pattern mining and collaborative filtering domains, namely negFIN, Alternating Least Squares, Bilateral Variational Autoencoder, and Collaborative Filtering based on Pearson's Correlation, Kendall and Spearman's Rank Correlation coefficients. The algorithms are compared on a real-world dataset supplied by a major recruitment company, Kariyer.net, from Turkey. The insights and methods gained through this work are expected to increase the efficiency and accuracy of various methods, such as recommending jobs or finding suitable candidates for open positions.
翻译:专业商业生活中的“部门”一词是一个模糊的概念,因为公司往往同时将自己视为在多个部门运作,这种模糊性在向求职者推荐工作或为公开职位寻找合适的候选人方面造成问题,后者在特定部门可供应聘的候选人也很少的情况下具有重要的意义;因此,从类似部门寻找候选人变得至关重要。这项工作的重点是通过关系分析发现可能的部门相似性。我们采用经常模式采矿和协作过滤领域的几种算法,即内弗林、交替最低广场、双边变换自动coder和根据皮尔森的关联、肯德尔和斯皮尔曼的相配系数合作过滤。算法是用土耳其一家大型招聘公司Kariyer.net提供的真实世界数据集进行比较的。通过这项工作获得的洞察力和方法可望提高各种方法的效率和准确性,例如推荐工作或为公开职位寻找合适的候选人。