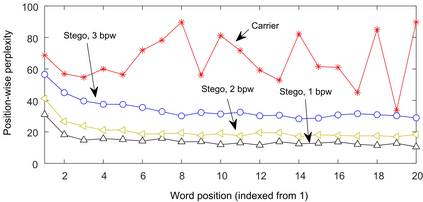
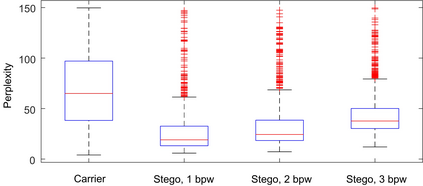
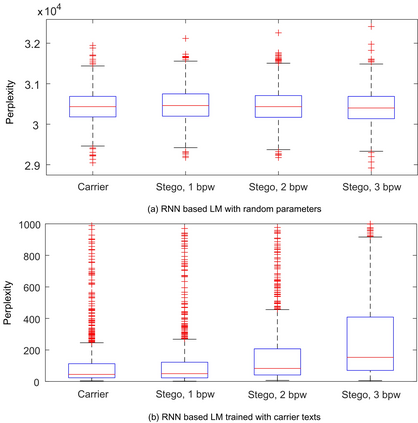
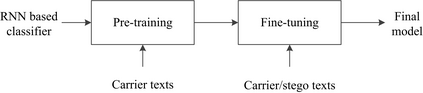
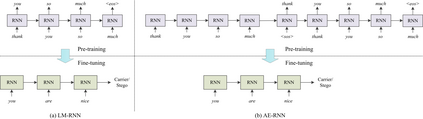
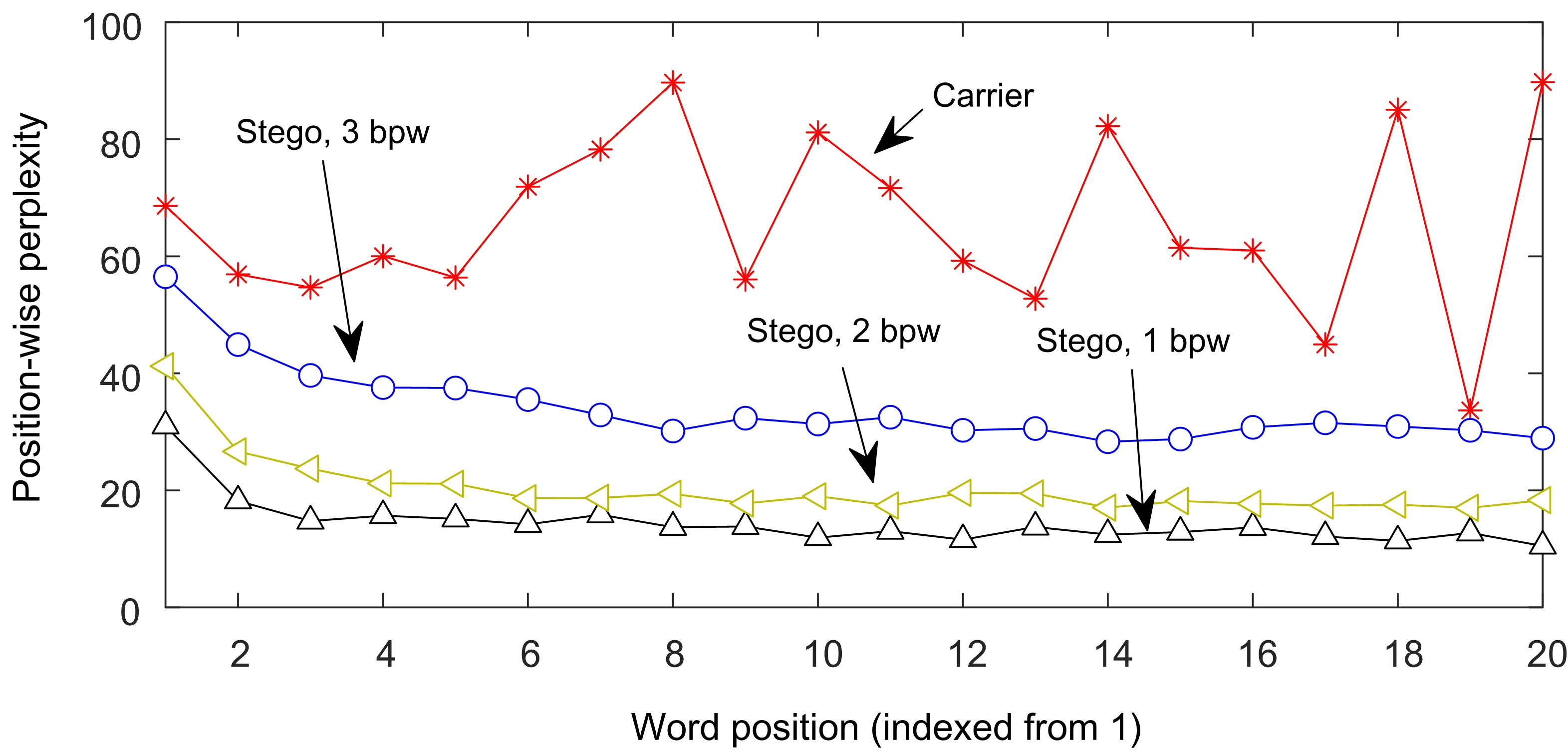
Recent advances in linguistic steganalysis have successively applied CNN, RNN, GNN and other efficient deep models for detecting secret information in generative texts. These methods tend to seek stronger feature extractors to achieve higher steganalysis effects. However, we have found through experiments that there actually exists significant difference between automatically generated stego texts and carrier texts in terms of the conditional probability distribution of individual words. Such kind of difference can be naturally captured by the language model used for generating stego texts. Through further experiments, we conclude that this ability can be transplanted to a text classifier by pre-training and fine-tuning to improve the detection performance. Motivated by this insight, we propose two methods for efficient linguistic steganalysis. One is to pre-train a language model based on RNN, and the other is to pre-train a sequence autoencoder. The results indicate that the two methods have different degrees of performance gain compared to the randomly initialized RNN, and the convergence speed is significantly accelerated. Moreover, our methods have achieved the state-of-the-art detection results.
翻译:在语言学分析方面最近的进展相继应用了CNN、RNN、GNN和其他高效的深度模型,以探测基因化文本中的机密信息,这些方法倾向于寻求更强的特征提取器,以达到更高的分解效果。然而,我们通过实验发现,在单词的有条件概率分布方面,自动生成的stego文本与承运人文本之间实际上存在很大差异。这种差异可以通过生成stego文本所使用的语言模型自然地捕捉到。通过进一步实验,我们得出结论,这种能力可以通过培训前和微调移植到文本分类器上,以提高检测性能。我们受这一洞察的启发,我们提出了两种高效的语言分解方法。其中一种是预演基于RNNN的语文模型,另一种是预演一个自动解码序列。结果显示,这两种方法的性能收益程度与随机初始的RNNN值不同,而趋同速度也大大加快。此外,我们的方法已经取得了最新技术检测结果。