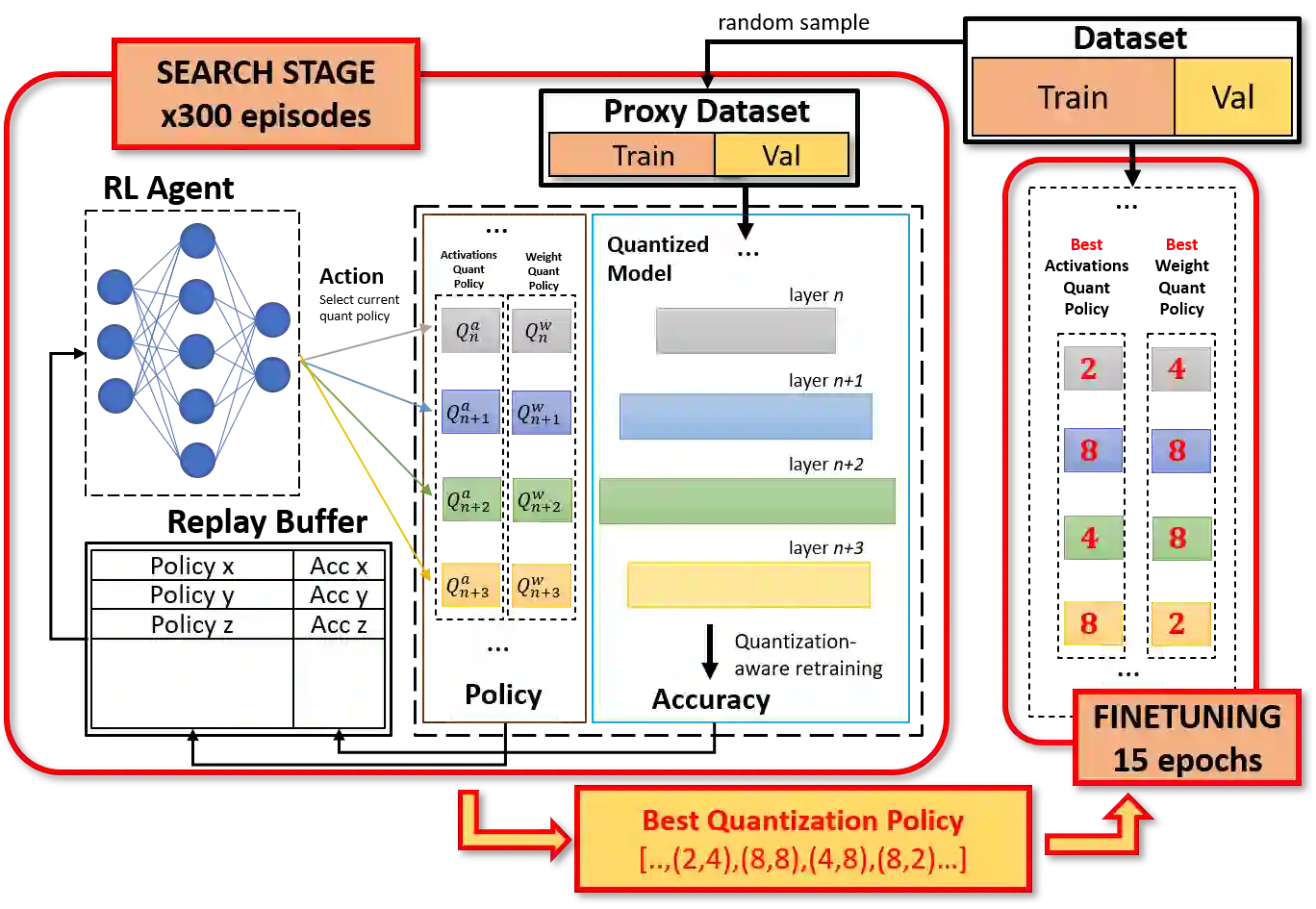
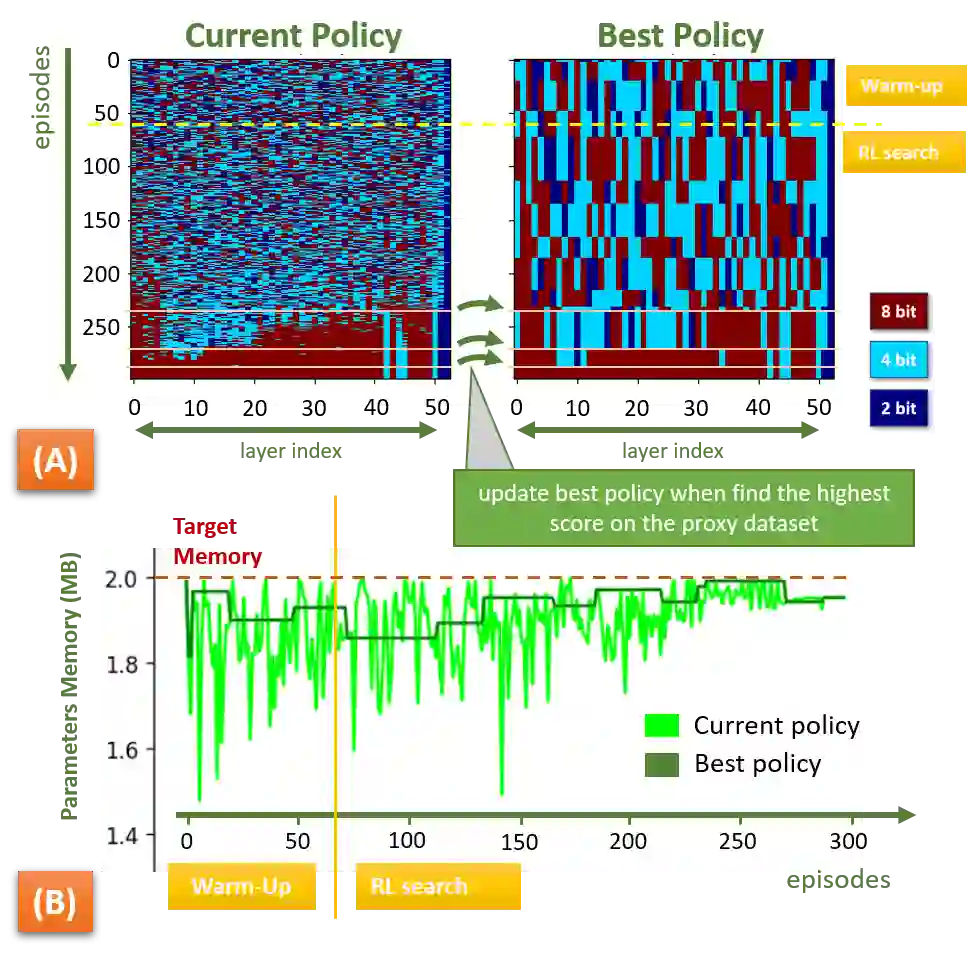
The severe on-chip memory limitations are currently preventing the deployment of the most accurate Deep Neural Network (DNN) models on tiny MicroController Units (MCUs), even if leveraging an effective 8-bit quantization scheme. To tackle this issue, in this paper we present an automated mixed-precision quantization flow based on the HAQ framework but tailored for the memory and computational characteristics of MCU devices. Specifically, a Reinforcement Learning agent searches for the best uniform quantization levels, among 2, 4, 8 bits, of individual weight and activation tensors, under the tight constraints on RAM and FLASH embedded memory sizes. We conduct an experimental analysis on MobileNetV1, MobileNetV2 and MNasNet models for Imagenet classification. Concerning the quantization policy search, the RL agent selects quantization policies that maximize the memory utilization. Given an MCU-class memory bound of 2MB for weight-only quantization, the compressed models produced by the mixed-precision engine result as accurate as the state-of-the-art solutions quantized with a non-uniform function, which is not tailored for CPUs featuring integer-only arithmetic. This denotes the viability of uniform quantization, required for MCU deployments, for deep weights compression. When also limiting the activation memory budget to 512kB, the best MobileNetV1 model scores up to 68.4% on Imagenet thanks to the found quantization policy, resulting to be 4% more accurate than the other 8-bit networks fitting the same memory constraints.
翻译:严重的芯片内存限制目前阻止了在微小微控制器(MICUs)中部署最准确的深神经网络模型(DNN),即使利用有效的8位位数的量化机制。为了解决这个问题,我们在本文件中根据HAQ框架展示了自动混合精度量化流,但为MCU设备的内存和计算特性定制。具体地说,在对RAM和FLAS嵌入的内存大小的严格限制下,强化学习代理物在2,4,8位数中搜索了个人重量和激活声纳的最精确度。我们对MPMNetV1、MPMNetV2和MNasNet用于图像网分类的模型进行了实验性分析。关于四分解政策搜索,RL代理商选择了最优化记忆利用的量化政策。鉴于MCU-级内存为2MB, 混合精度引擎生成的压缩模型准确度为RAMV的状态溶解度溶解度,其最精确的内嵌化的内存能力为5位数级CU1,其最精确的缩缩缩缩缩的缩缩缩缩缩缩缩缩缩缩缩缩缩缩的CU。