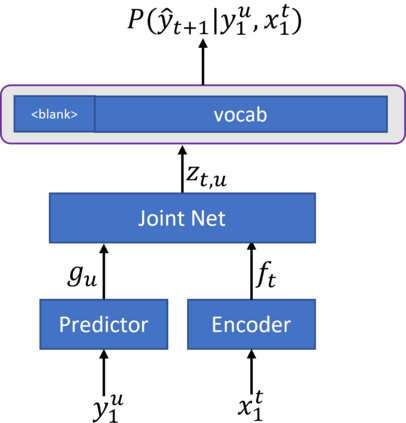
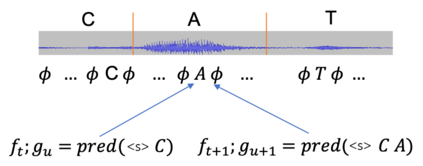
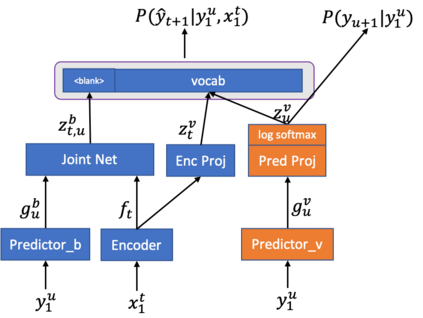
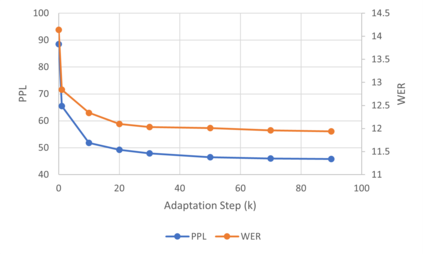
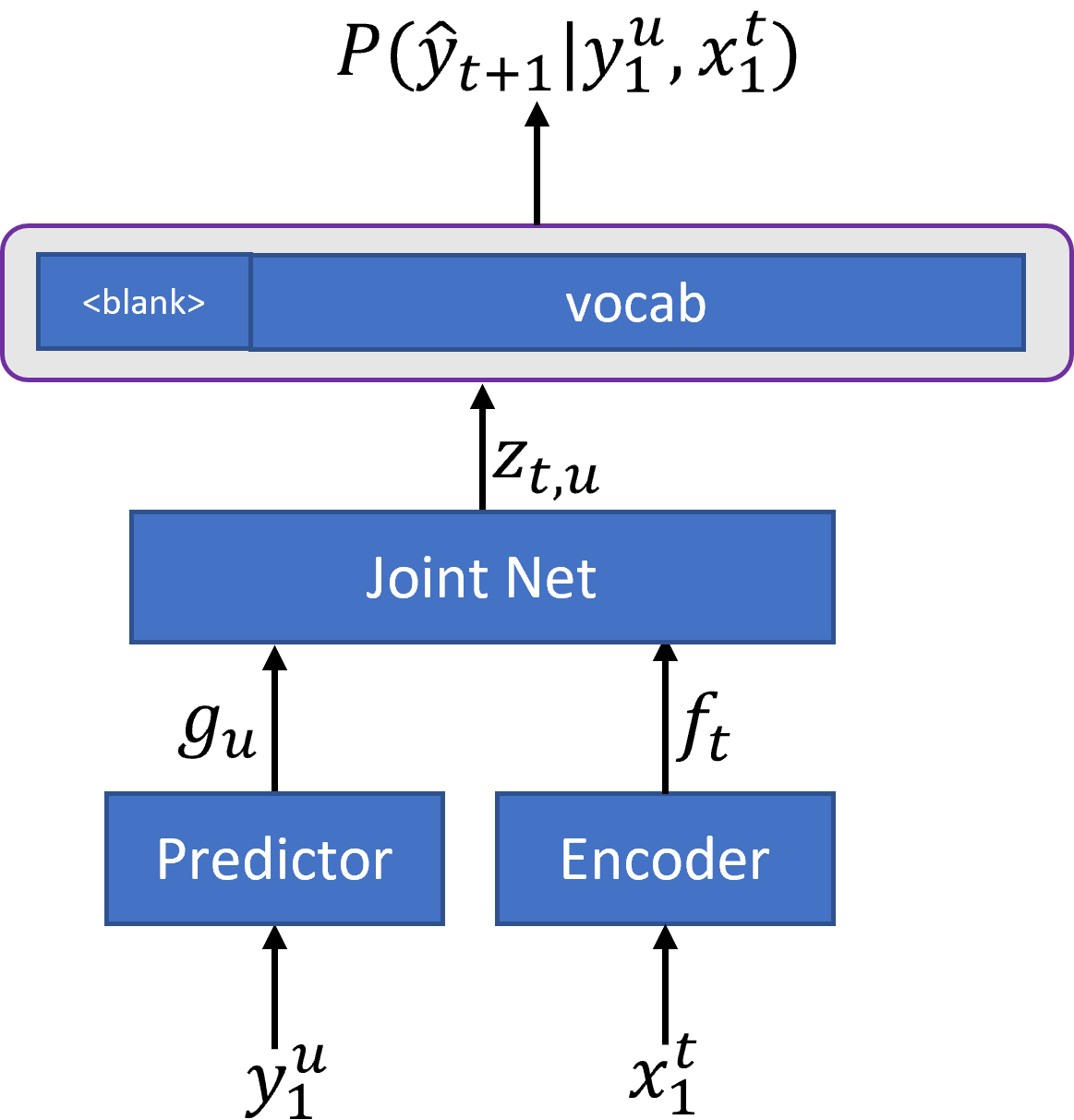
In recent years, end-to-end (E2E) based automatic speech recognition (ASR) systems have achieved great success due to their simplicity and promising performance. Neural Transducer based models are increasingly popular in streaming E2E based ASR systems and have been reported to outperform the traditional hybrid system in some scenarios. However, the joint optimization of acoustic model, lexicon and language model in neural Transducer also brings about challenges to utilize pure text for language model adaptation. This drawback might prevent their potential applications in practice. In order to address this issue, in this paper, we propose a novel model, factorized neural Transducer, by factorizing the blank and vocabulary prediction, and adopting a standalone language model for the vocabulary prediction. It is expected that this factorization can transfer the improvement of the standalone language model to the Transducer for speech recognition, which allows various language model adaptation techniques to be applied. We demonstrate that the proposed factorized neural Transducer yields 15% to 20% WER improvements when out-of-domain text data is used for language model adaptation, at the cost of a minor degradation in WER on a general test set.
翻译:近年来,基于终端到终端(E2E)的自动语音识别(ASR)系统由于其简洁和有希望的性能而取得了巨大成功。基于神经转换器的模型在基于E2E的ASR系统流中越来越受欢迎,据报告在某些情景中超过了传统的混合系统。然而,神经转换器的声学模型、词典和语言模型的联合优化也带来了使用纯文本进行语言模式调整的挑战。这一缺陷可能会妨碍其实际应用。为了解决这一问题,我们在本文件中提出了一个新颖的模型,即因数神经转换器,将空白和词汇预测考虑在内,并采用独立的语言模型来进行词汇预测。预计这一系数化可以将独立语言模型的改进转移到音学感化器,从而允许应用各种语言模型适应技术。我们证明,在使用外部文本数据进行语言模型调整时,按要素化神经转换器将产生15%至20%的改进。这样做的代价是,WER在一般测试中WER数据集中进行轻微退化。