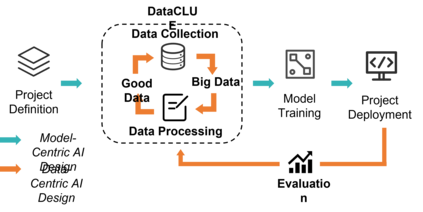
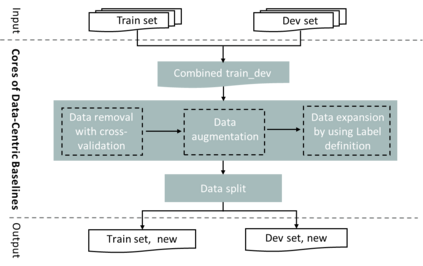
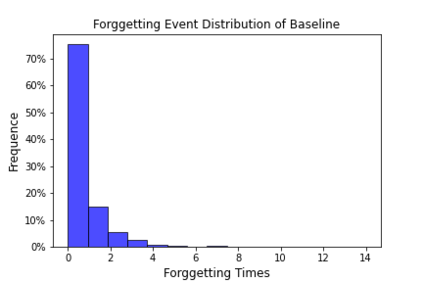
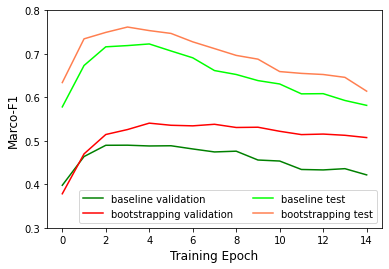
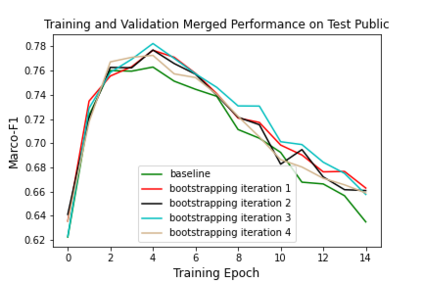
Data-centric AI has recently proven to be more effective and high-performance, while traditional model-centric AI delivers fewer and fewer benefits. It emphasizes improving the quality of datasets to achieve better model performance. This field has significant potential because of its great practicability and getting more and more attention. However, we have not seen significant research progress in this field, especially in NLP. We propose DataCLUE, which is the first Data-Centric benchmark applied in NLP field. We also provide three simple but effective baselines to foster research in this field (improve Macro-F1 up to 5.7% point). In addition, we conduct comprehensive experiments with human annotators and show the hardness of DataCLUE. We also try an advanced method: the forgetting informed bootstrapping label correction method. All the resources related to DataCLUE, including dataset, toolkit, leaderboard, and baselines, is available online at https://github.com/CLUEbenchmark/DataCLUE
翻译:以数据为中心的AI最近证明是更加有效和高性能的,而传统的以模式为中心的AI提供的效益越来越少,也越来越少。它强调提高数据集的质量,以取得更好的模型性能。这个领域具有巨大的潜力,因为它非常实用,而且越来越受到更多的关注。然而,我们没有看到这一领域的重大研究进展,特别是在NLP。我们提议DataCLUE,这是在NLP领域应用的第一个数据中心基准。我们还提供了三个简单而有效的基准,以促进这一领域的研究(在5.7%点至5.7%点之间推广宏观-F1)。此外,我们与人类计票员进行了全面实验,并展示了数据CLUE的硬性。我们还尝试了一种先进的方法:忘记知情靴式标签校正方法。所有与数据CLUE有关的资源,包括数据集、工具包、领导板和基线,都可以在https://github.com/CLUEbenchmark/DataCLUE上查阅。