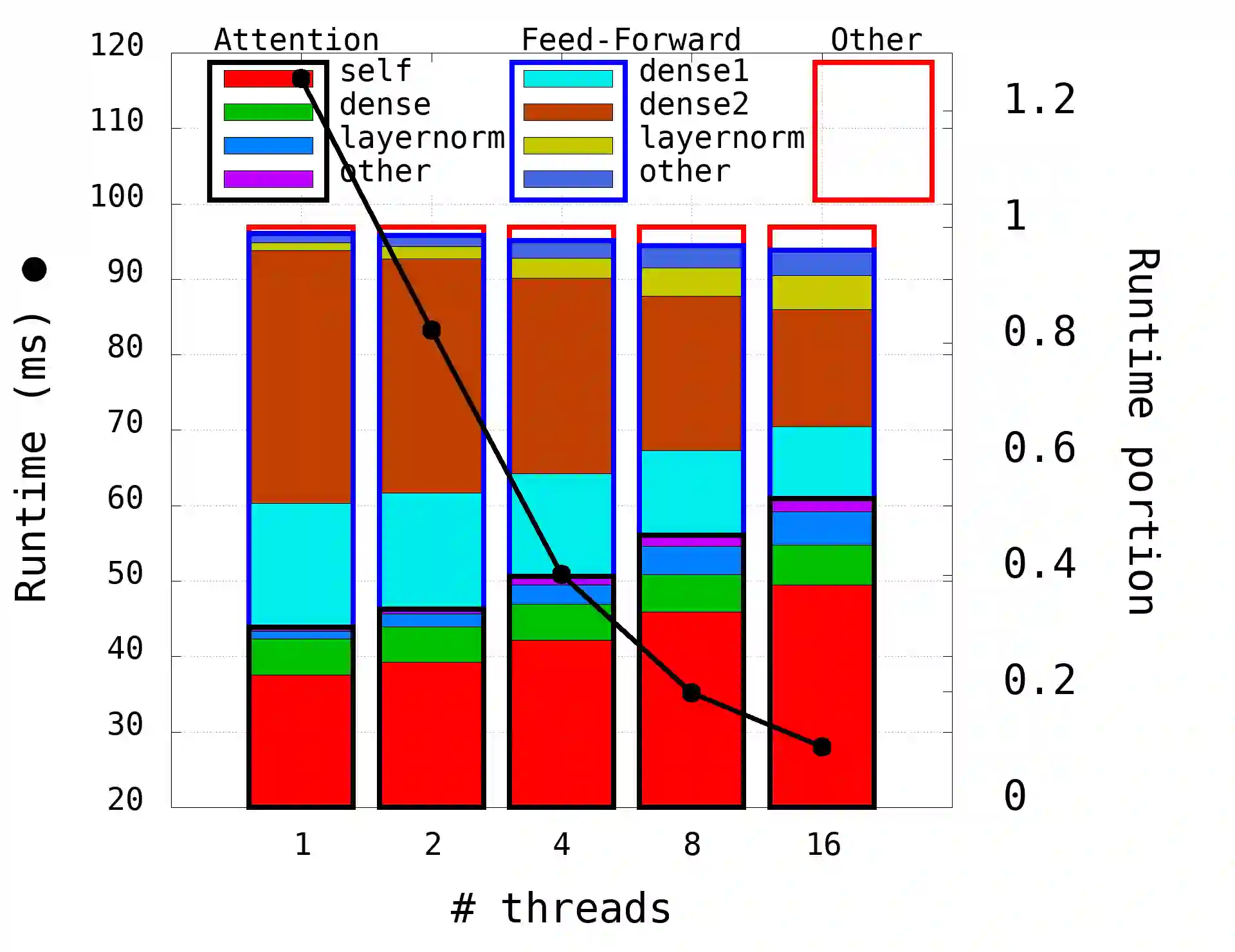
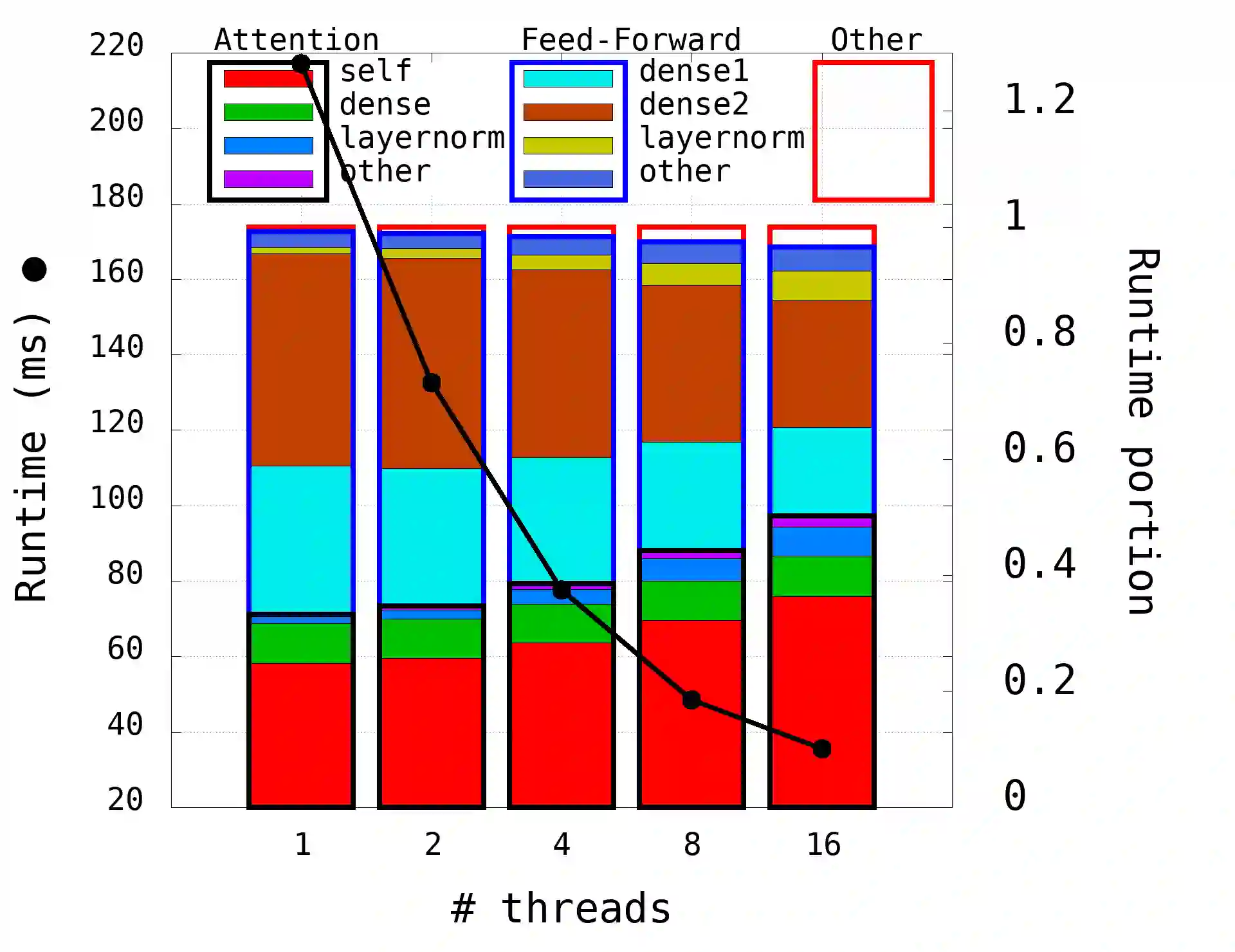
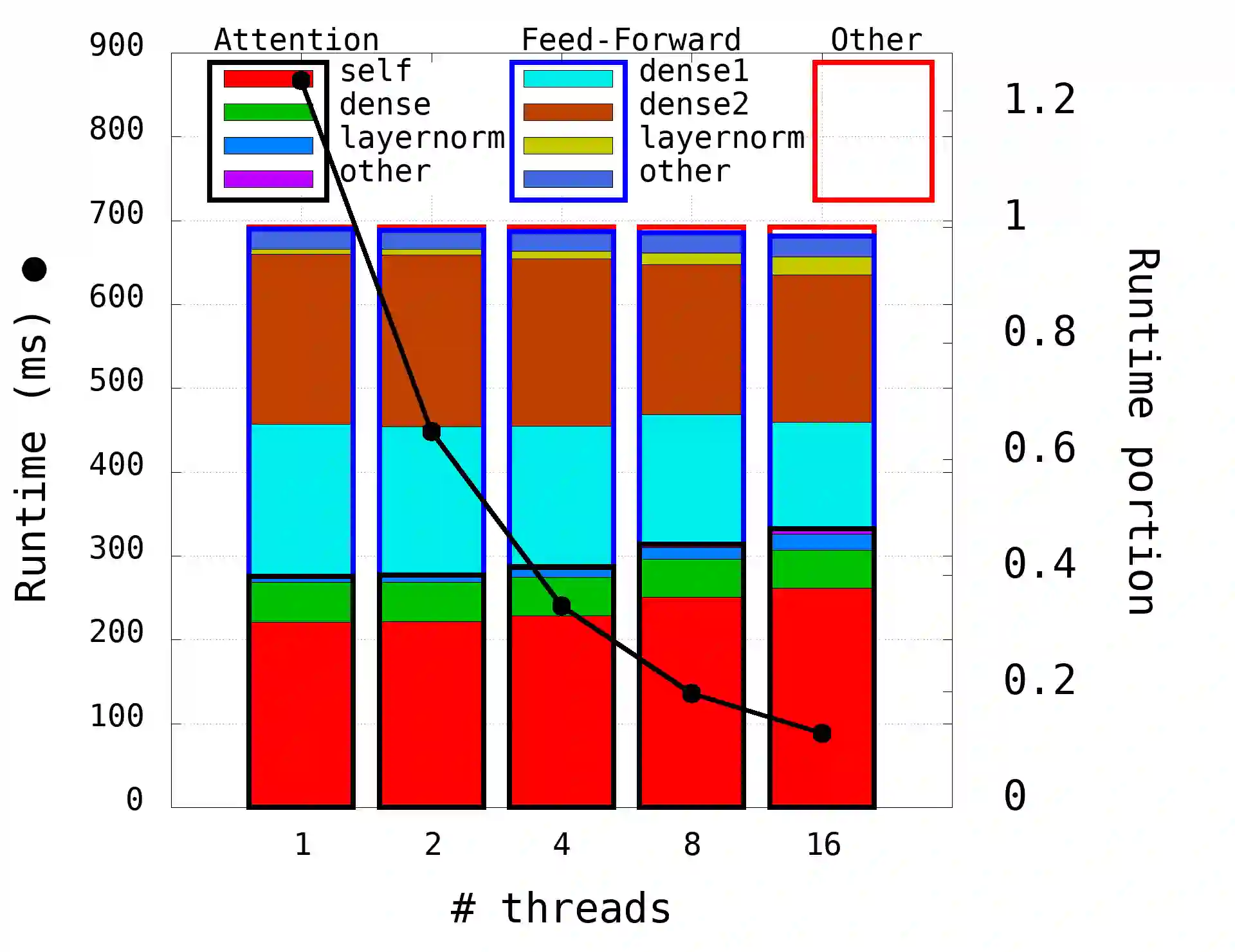
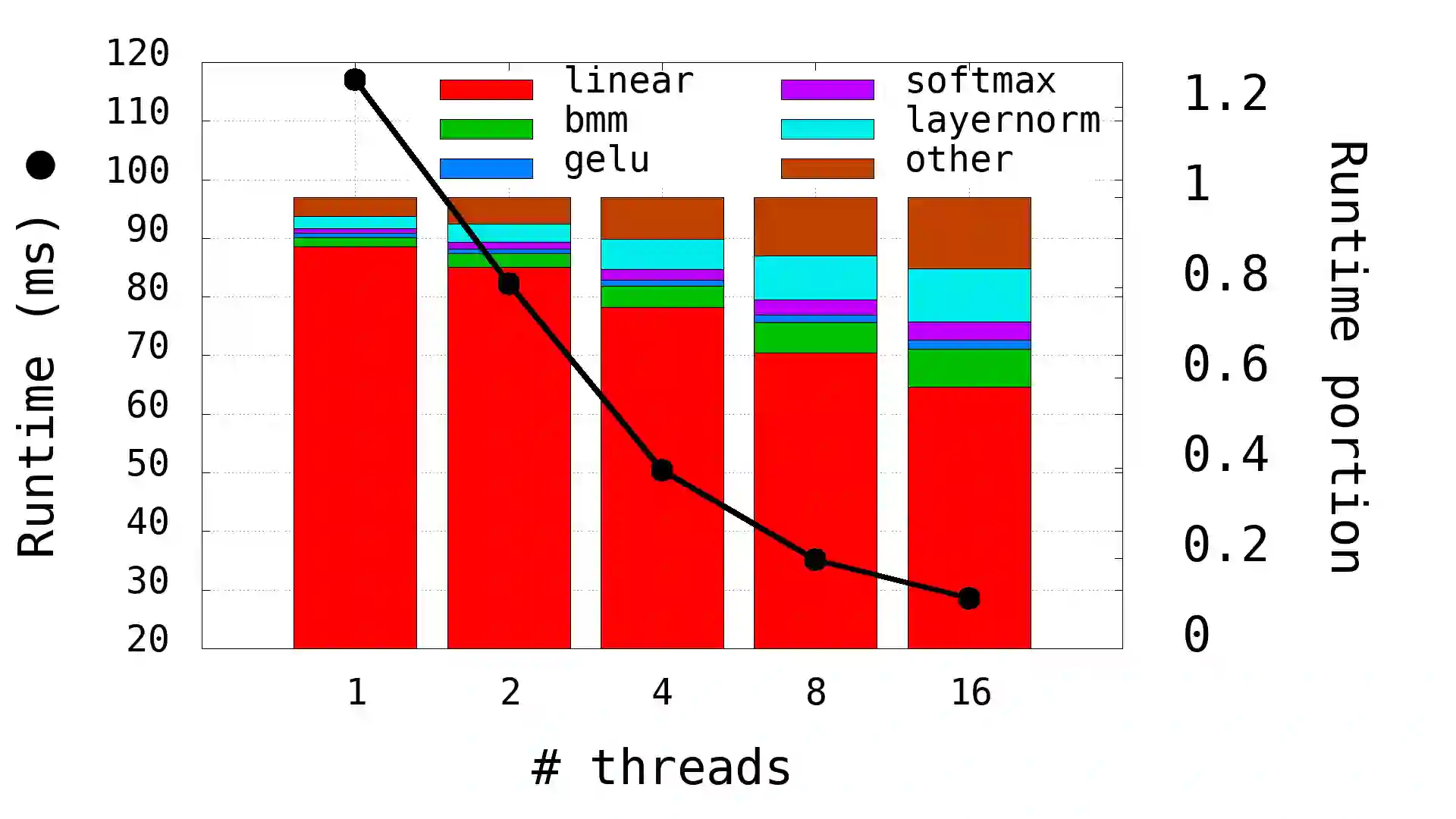
The Transformer architecture revolutionized the field of natural language processing (NLP). Transformers-based models (e.g., BERT) power many important Web services, such as search, translation, question-answering, etc. While enormous research attention is paid to the training of those models, relatively little efforts are made to improve their inference performance. This paper comes to address this gap by presenting an empirical analysis of scalability and performance of inferencing a Transformer-based model on CPUs. Focusing on the highly popular BERT model, we identify key components of the Transformer architecture where the bulk of the computation happens, and propose three optimizations to speed them up. The optimizations are evaluated using the inference benchmark from HuggingFace, and are shown to achieve the speedup of up to x2.36. The considered optimizations do not require any changes to the implementation of the models nor affect their accuracy.
翻译:变换器结构将自然语言处理领域(NLP)革命化。以变换器为基础的模型(例如BERT)使许多重要的网络服务,例如搜索、翻译、问答等。虽然对这些模型的培训给予了巨大的研究关注,但相对而言,为改进这些模型的推论性能所作的努力相对较少。本文通过对基于变换器的CPU模型的推论性能和性能进行经验性分析来弥补这一差距。我们侧重于广受欢迎的BERT模型,我们确定了变换器结构中大部分计算的关键组成部分,并提出了三种优化以加速这些结构。优化是利用HuggingFace的推论基准进行评估的,并表明优化可以达到x2.36的加速速度。经过考虑的优化并不要求对模型的实施作任何改变,也不影响其准确性。