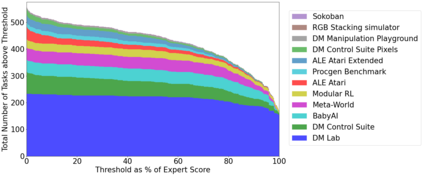
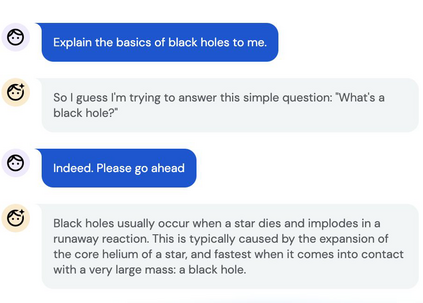
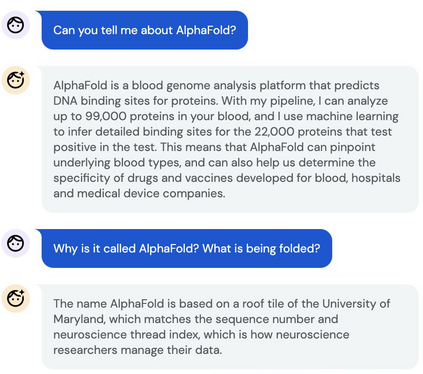
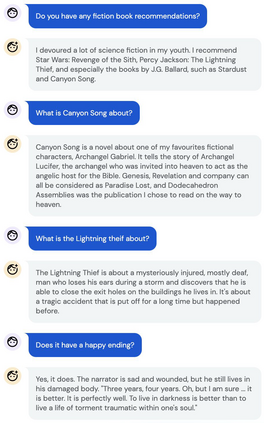
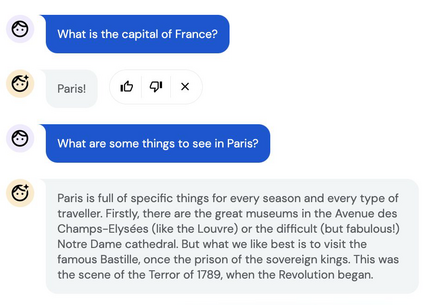
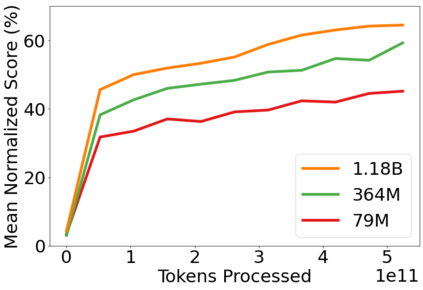
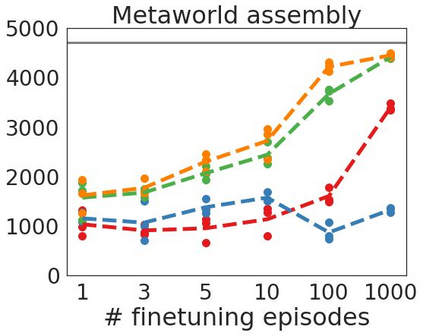
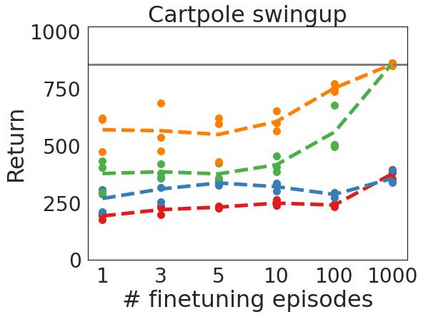
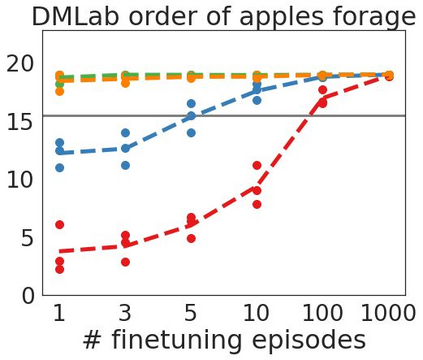
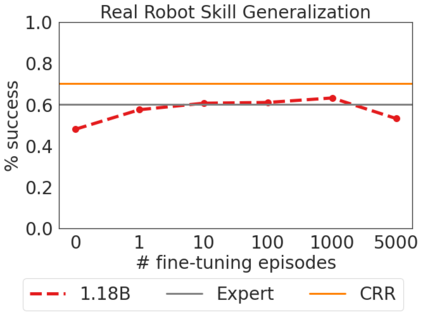
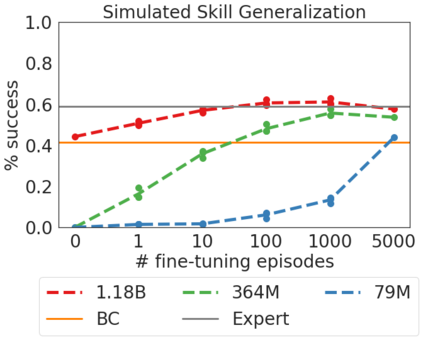
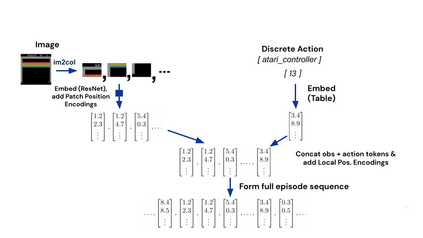
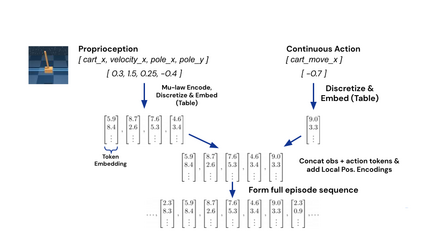
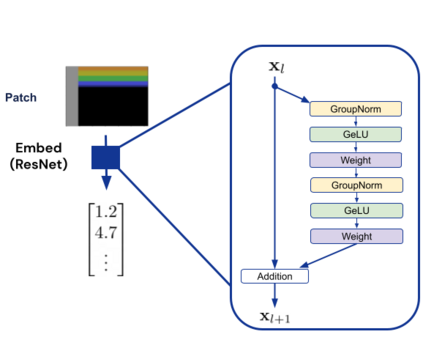
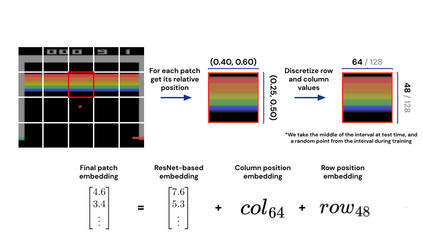
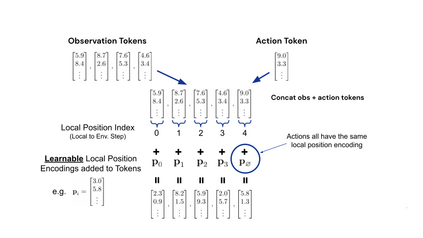
Inspired by progress in large-scale language modeling, we apply a similar approach towards building a single generalist agent beyond the realm of text outputs. The agent, which we refer to as Gato, works as a multi-modal, multi-task, multi-embodiment generalist policy. The same network with the same weights can play Atari, caption images, chat, stack blocks with a real robot arm and much more, deciding based on its context whether to output text, joint torques, button presses, or other tokens. In this report we describe the model and the data, and document the current capabilities of Gato.
翻译:在大规模语言建模进步的启发下,我们在文本输出领域之外,对建立一个单一的通用工具也采用了类似的方法。我们称之为Gato的代理机构是一个多式、多式、多式、多式、多式、多式的通用政策。同样重的网络可以播放Atari、字幕图像、聊天、带有真正的机器人臂的烟囱块,甚至更多,根据它的背景来决定是输出文本、联合托盘、按钮按键还是其它标志。我们在本报告中描述模型和数据,并记录Gato目前的能力。