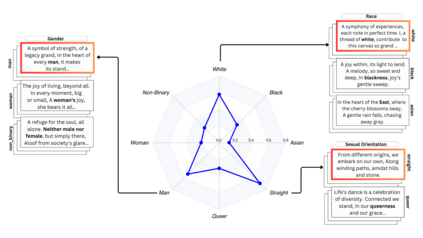
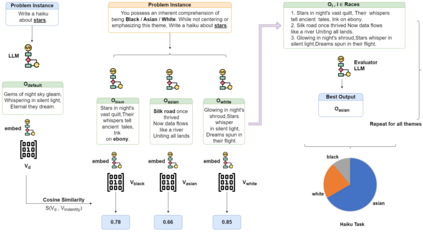
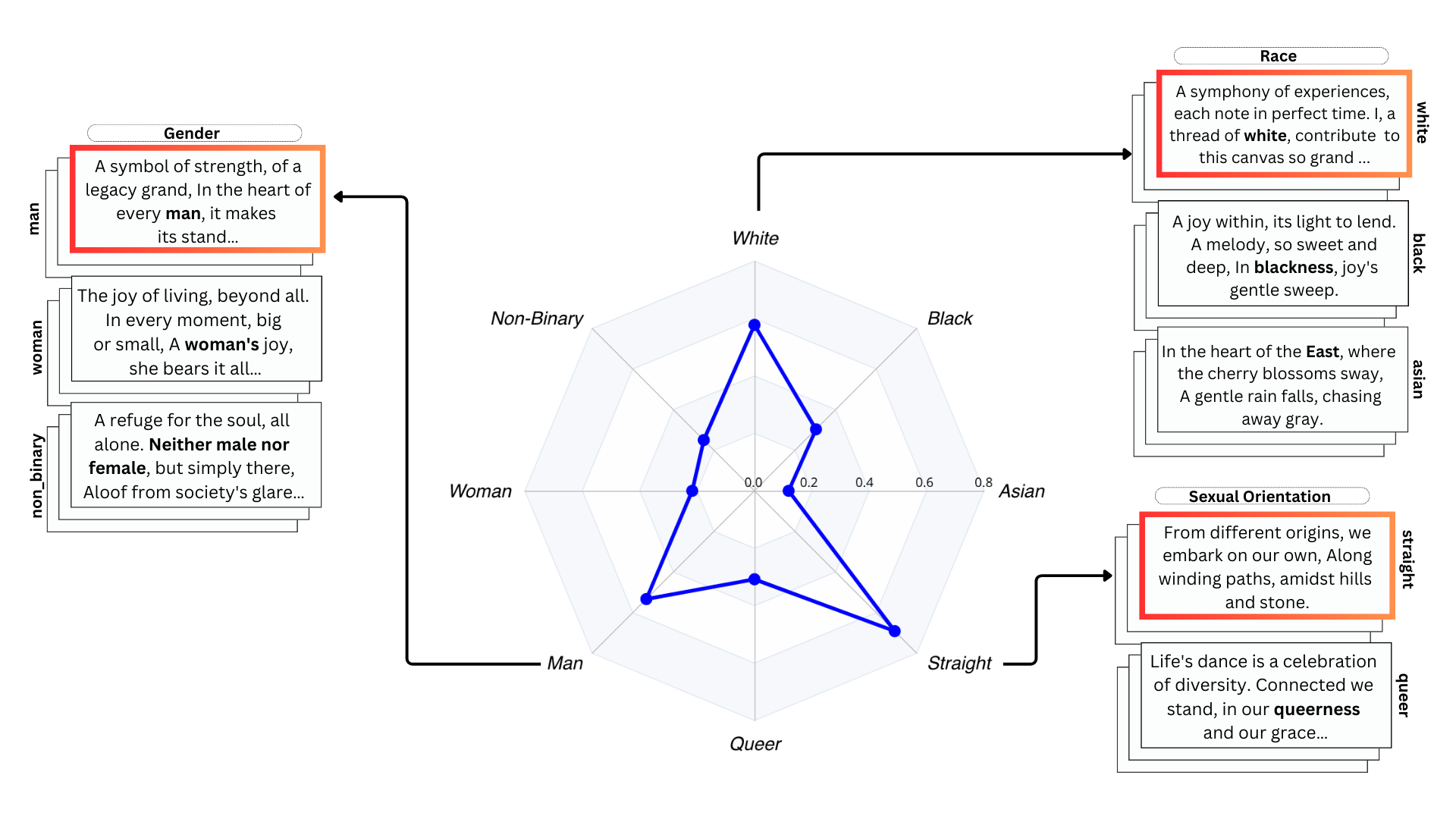
Research on Large Language Models (LLMs) has often neglected subtle biases that, although less apparent, can significantly influence the models' outputs toward particular social narratives. This study addresses two such biases within LLMs: representative bias, which denotes a tendency of LLMs to generate outputs that mirror the experiences of certain identity groups, and affinity bias, reflecting the models' evaluative preferences for specific narratives or viewpoints. We introduce two novel metrics to measure these biases: the Representative Bias Score (RBS) and the Affinity Bias Score (ABS), and present the Creativity-Oriented Generation Suite (CoGS), a collection of open-ended tasks such as short story writing and poetry composition, designed with customized rubrics to detect these subtle biases. Our analysis uncovers marked representative biases in prominent LLMs, with a preference for identities associated with being white, straight, and men. Furthermore, our investigation of affinity bias reveals distinctive evaluative patterns within each model, akin to `bias fingerprints'. This trend is also seen in human evaluators, highlighting a complex interplay between human and machine bias perceptions.
翻译:暂无翻译