
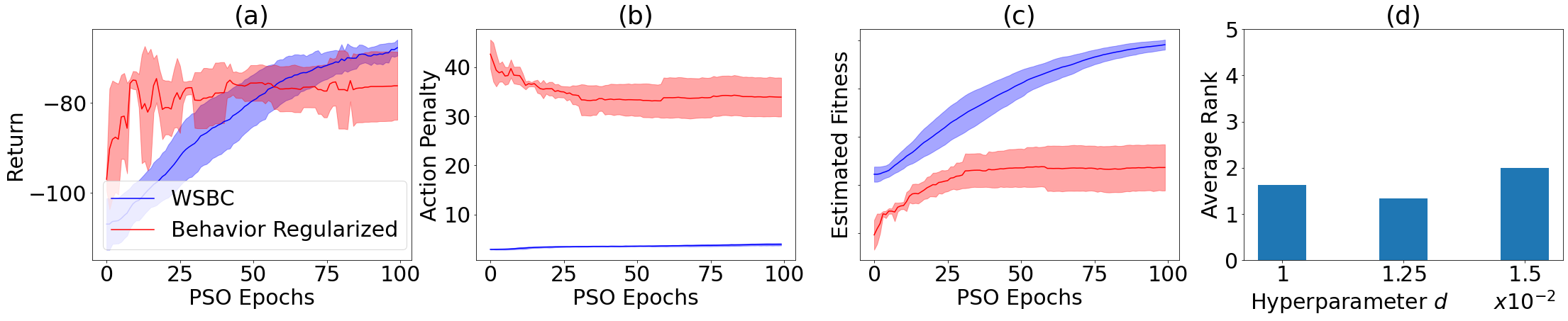
In offline reinforcement learning, a policy needs to be learned from a single pre-collected dataset. Typically, policies are thus regularized during training to behave similarly to the data generating policy, by adding a penalty based on a divergence between action distributions of generating and trained policy. We propose a new algorithm, which constrains the policy directly in its weight space instead, and demonstrate its effectiveness in experiments.
翻译:在离线强化学习中,需要从一个收集前的数据集中学习一项政策。 一般来说,在培训期间,将政策正规化,使其与数据生成政策相似,根据生成政策的行动分布和受过培训的政策之间的差异而加罚。 我们提出了一个新的算法,它直接限制政策的权重空间,并在实验中展示其有效性。
相关内容
Arxiv
8+阅读 · 2021年8月24日
Arxiv
4+阅读 · 2019年3月19日
Arxiv
4+阅读 · 2018年1月29日



相关VIP内容
相关资讯
相关论文
Arxiv
8+阅读 · 2021年8月24日
Arxiv
4+阅读 · 2019年3月19日
Arxiv
4+阅读 · 2018年1月29日