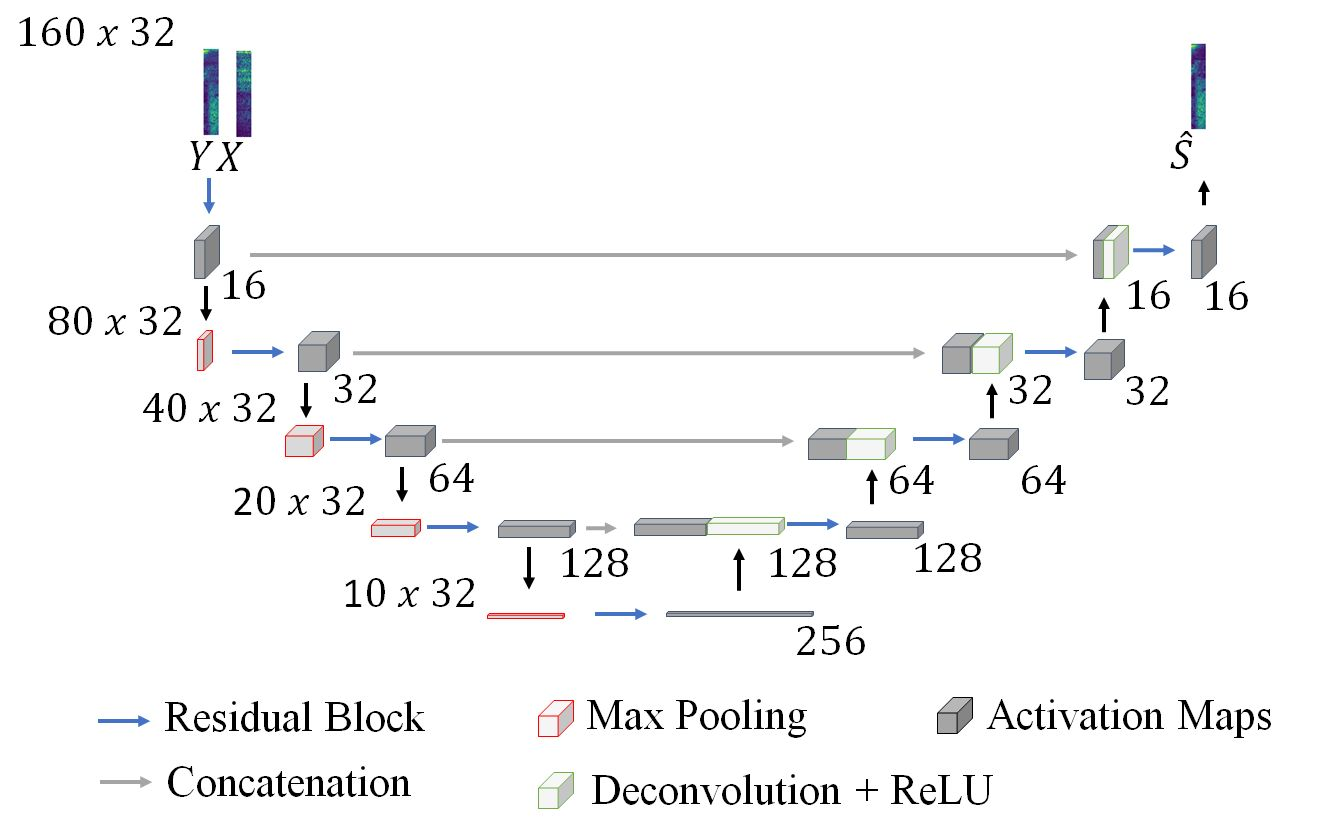
This paper presents an acoustic echo canceler based on a U-Net convolutional neural network for single-talk and double-talk scenarios. U-Net networks have previously been used in the audio processing area for source separation problems because of their ability to reproduce the finest details of audio signals, but to our knowledge, this is the first time they have been used for acoustic echo cancellation (AEC). The U-Net hyperparameters have been optimized to obtain the best AEC performance, but using a reduced number of parameters to meet a latency restriction of 40 ms. The training and testing of our model have been carried out within the framework of the 'ICASSP 2021 AEC Challenge' organized by Microsoft. We have trained the optimized U-Net model with a synthetic dataset only (S-U-Net) and with a synthetic dataset and the single-talk set of a real dataset (SR-U-Net), both datasets were released for the challenge. The S-U-Net model presented better results for double-talk scenarios, thus their inferred near-end signals from the blind testset were submitted to the challenge. Our canceler ranked 12th among 17 teams, and 5th among 10 academia teams, obtaining an overall mean opinion score of 3.57.
翻译:本文展示了基于U-Net Convolutional神经网络的声学回声取消器,用于单声带和双声带情景。U-Net网络以前曾用于音频处理区处理源分离问题,因为它们能够复制最精细的音频信号,但据我们所知,这是首次使用这些网络来取消音频回声(AEC),U-Net超光谱仪是为了获得最佳的AEC性能而优化的,但使用数量较少的参数来达到40米的拉特限制。我们模型的培训和测试是在微软组织的“ICASSP 2021 AEC挑战”的框架内进行的。我们仅用合成数据集(S-U-Net)和合成数据集和真实数据集(SR-U-Net)的单声集来培训优化的U-Net模型,两种数据集都为挑战而发布。S-U-Net模型为双声带情景提供了更好的结果,因此在微调测试组中推断出近端信号。我们仅使用合成数据集(S-U-Net-Net-Net-Net-Net)的优化U-Net模型培训了优化的U-Net模型模型。我们第10位排名第17组之间的意见。