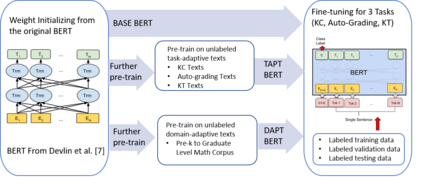
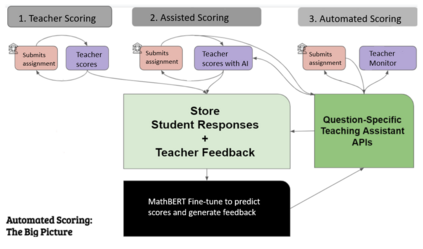
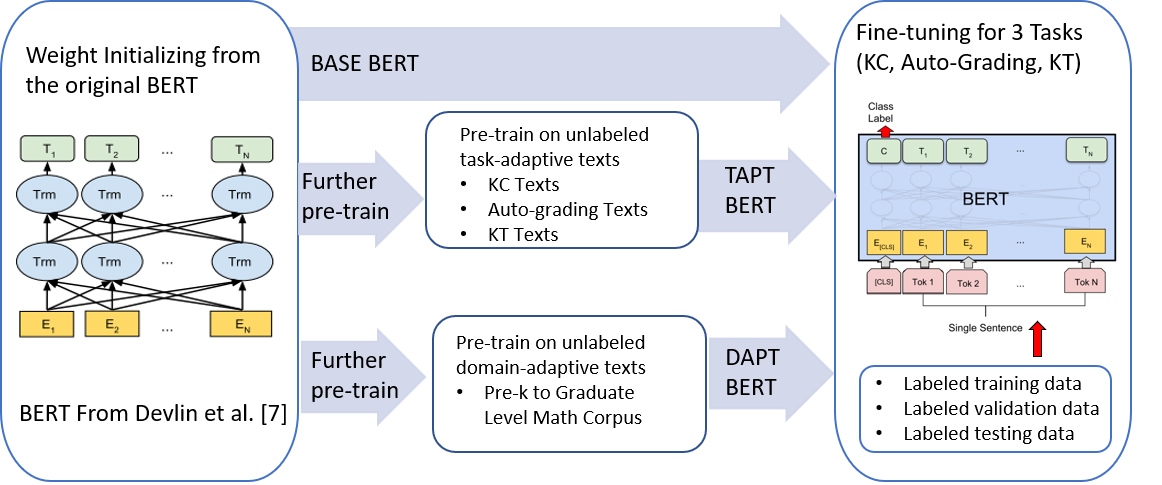
Since the introduction of the original BERT (i.e., BASE BERT), researchers have developed various customized BERT models with improved performance for specific domains and tasks by exploiting the benefits of {\em transfer learning}. Due to the nature of mathematical texts, which often use domain specific vocabulary along with equations and math symbols, we posit that the development of a new BERT model for mathematics would be useful for many mathematical downstream tasks. In this resource paper, we introduce our multi-institutional effort (i.e., two learning platforms and three academic institutions in the US) toward this need: MathBERT, a model created by pre-training the BASE BERT model on a large mathematical corpus ranging from pre-kindergarten (pre-k), to high-school, to college graduate level mathematical content. In addition, we select three general NLP tasks that are often used in mathematics education: prediction of knowledge component, auto-grading open-ended Q\&A, and knowledge tracing, to demonstrate the superiority of MathBERT over BASE BERT. Our experiments show that MathBERT outperforms prior best methods by 1.2-22\% and BASE BERT by 2-8\% on these tasks. In addition, we build a mathematics specific vocabulary `mathVocab' to train with MathBERT. We discover that MathBERT pre-trained with `mathVocab' outperforms MathBERT trained with the BASE BERT vocabulary (i.e., `origVocab'). MathBERT is currently being adopted at the participated leaning platforms: Stride, Inc, a commercial educational resource provider, and ASSISTments.org, a free online educational platform. We release MathBERT for public usage at: https://github.com/tbs17/MathBERT.
翻译:自最初的BERT (即BASE BERT) 推出以来,研究人员开发了各种定制的BERT模型,通过利用 Expending 学习的收益,提高了特定领域和任务的绩效。由于数学文本的性质,常常使用域特定词汇以及方程和数学符号,我们假设开发新的BERT数学模型将有益于许多数学下游任务。在本资源文件中,我们为这一需要引入了我们的多机构努力(即,美国的两个学习平台和三个学术机构) : MathBERT, 预培训BASE BER模型所创建的关于特定领域和任务的模型:从预开学前(k-k)到高中,到大学研究生的数学内容。此外,我们选择了三种通常用于数学教育的通用NLP任务:知识组成部分的预测、开放的自动升级 ⁇ A,以及知识追踪,以显示MathBERT比STERER公司更高级。我们的实验显示,在WATERT Exest 方法中,B_B'ma/BASANSB 建立特定的数学数据库。