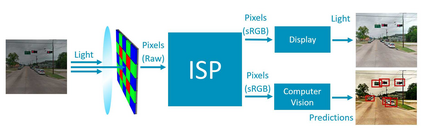
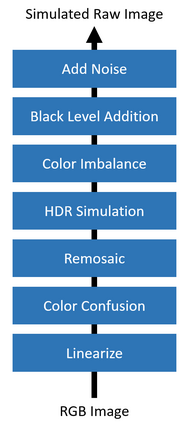
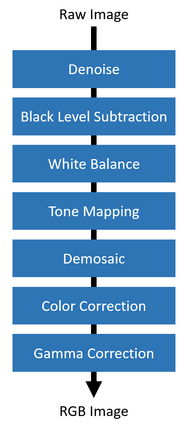
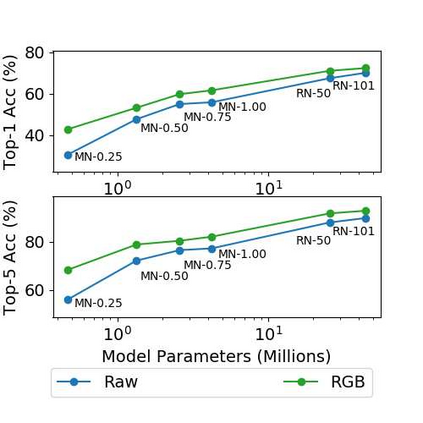
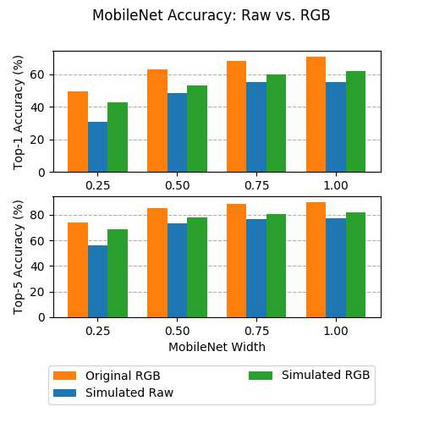
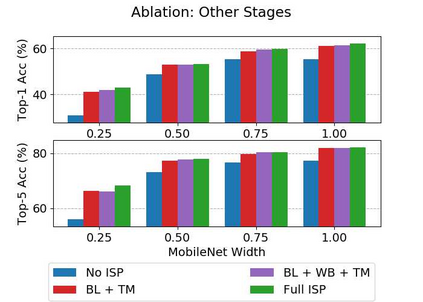
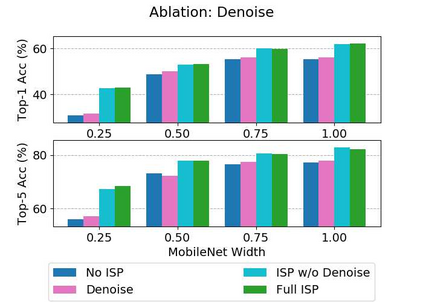
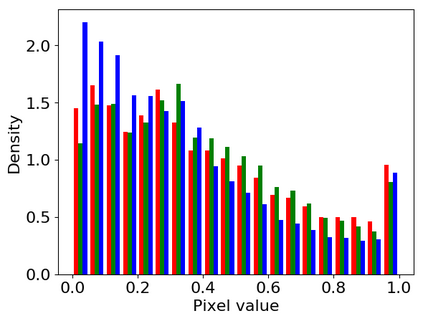
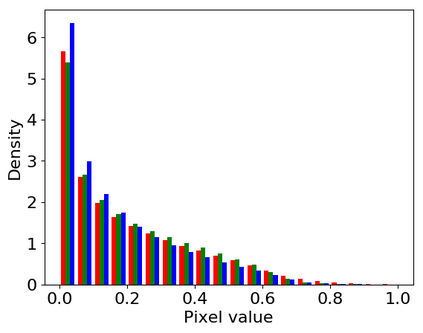
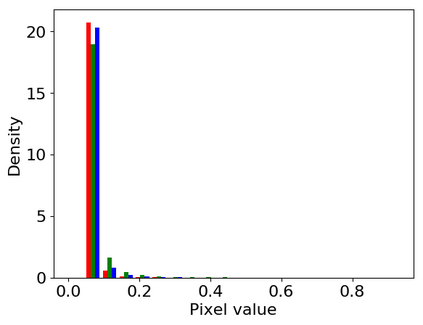
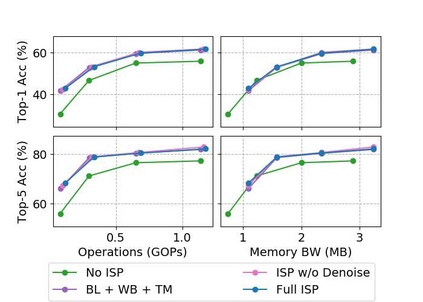
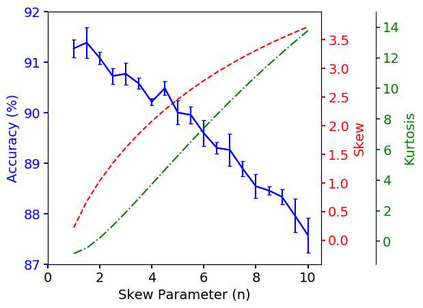
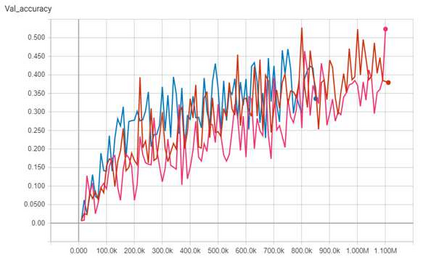
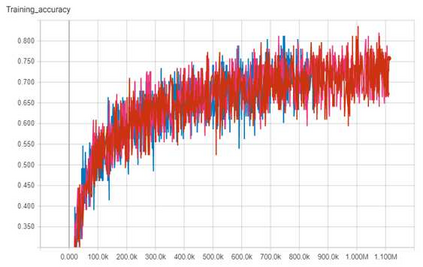
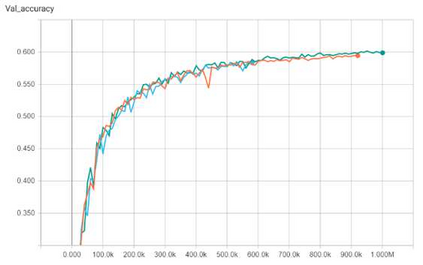
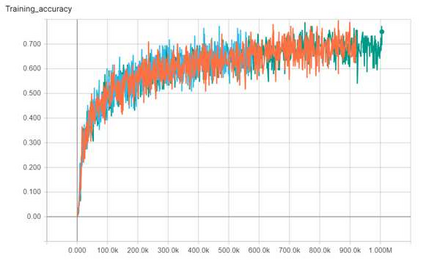
Convolutional neural networks (CNNs) are now predominant components in a variety of computer vision (CV) systems. These systems typically include an image signal processor (ISP), even though the ISP is traditionally designed to produce images that look appealing to humans. In CV systems, it is not clear what the role of the ISP is, or if it is even required at all for accurate prediction. In this work, we investigate the efficacy of the ISP in CNN classification tasks, and outline the system-level trade-offs between prediction accuracy and computational cost. To do so, we build software models of a configurable ISP and an imaging sensor in order to train CNNs on ImageNet with a range of different ISP settings and functionality. Results on ImageNet show that an ISP improves accuracy by 4.6%-12.2% on MobileNet architectures of different widths. Results using ResNets demonstrate that these trends also generalize to deeper networks. An ablation study of the various processing stages in a typical ISP reveals that the tone mapper is the most significant stage when operating on high dynamic range (HDR) images, by providing 5.8% average accuracy improvement alone. Overall, the ISP benefits system efficiency because the memory and computational costs of the ISP is minimal compared to the cost of using a larger CNN to achieve the same accuracy.
翻译:在各种计算机视觉系统(CV)中,这些系统通常包括一个图像信号处理器(ISP)的软件模型和成像传感器,以在图像网络上培训有线电视新闻网,其设置和功能各不相同。在CV系统中,不清楚ISP的作用是什么,或者是否甚至需要它来准确预测。在这项工作中,我们调查ISP在CNN分类任务中的功效,并概述系统一级预测准确性和计算成本之间的取舍。为此,我们建造了一个可配置ISP和成像传感器的软件模型,以便用各种ISP设置和功能在图像网络上培训CNNs。在图像网络上的结果显示,ISP在不同宽度的移动网络结构中提高了4.6%至12.2%的准确度。使用ResNet的结果显示,这些趋势也普遍到更深的网络。对典型ISP的各个处理阶段进行对比研究表明,在高动态范围操作时,音调制图仪是最重要的阶段(HDR),用不同的ISP设置和更大的图像进行图像的精确度,因为对ISP的精确度进行了比较,只有5.8%的精确度改进,因为I的精确度是I的完整的精确度,只有I的精确度才能进行整个的计算。