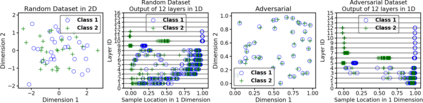
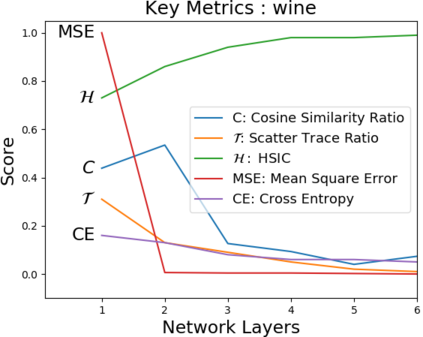
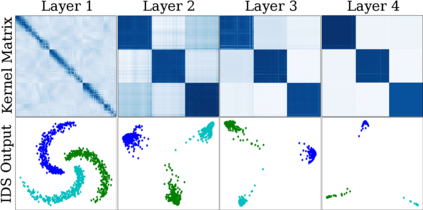
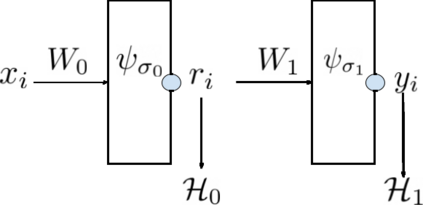
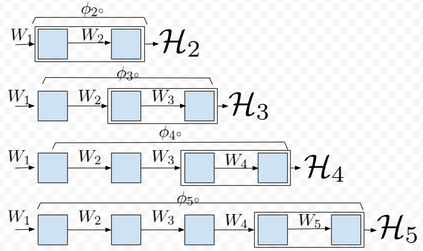
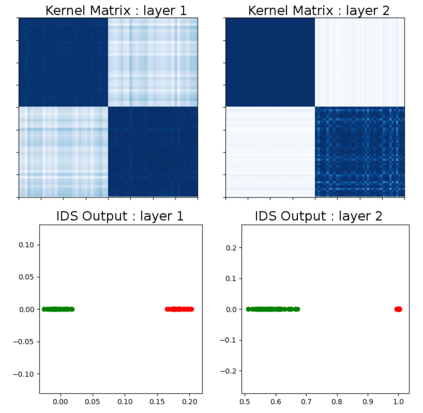
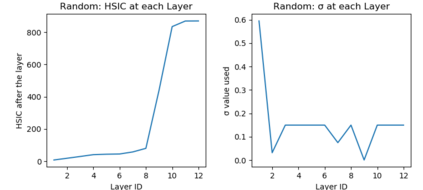
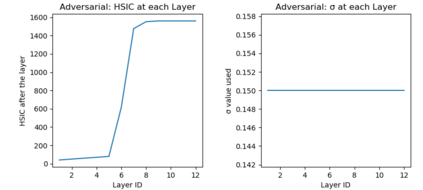
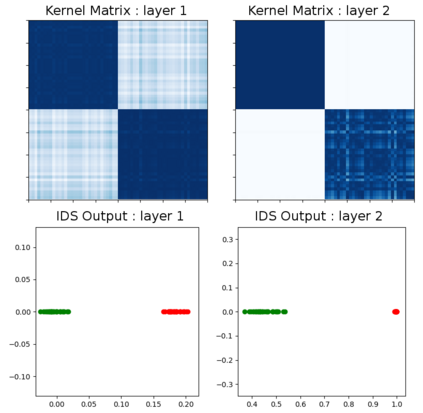
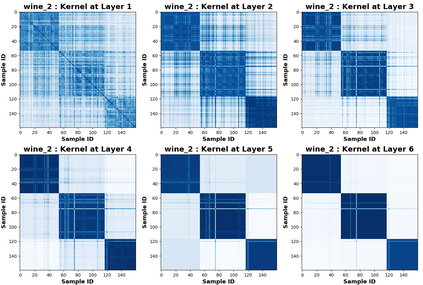
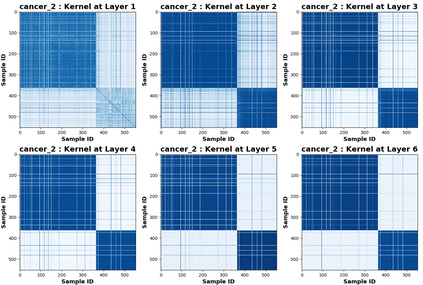
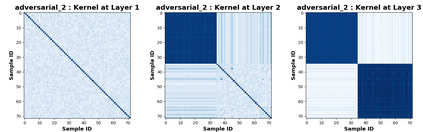
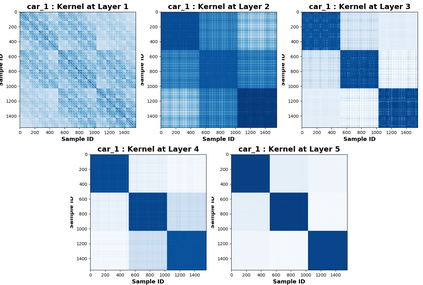
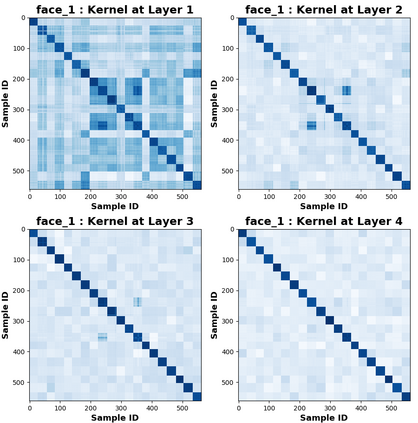
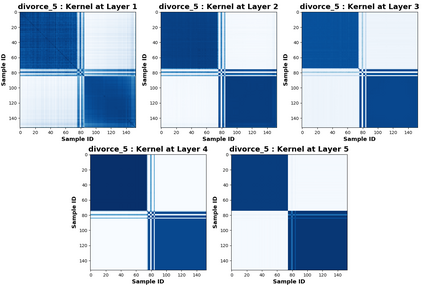
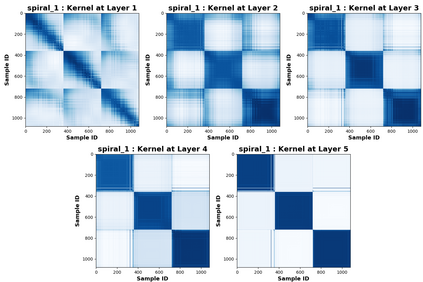
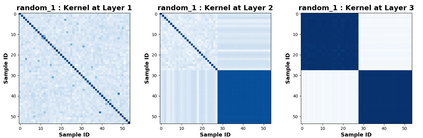
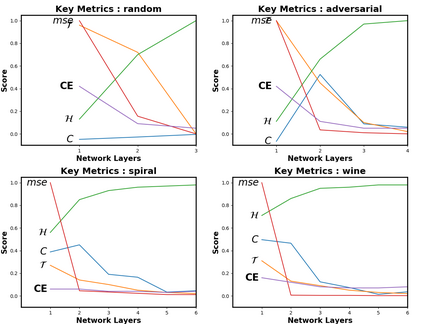
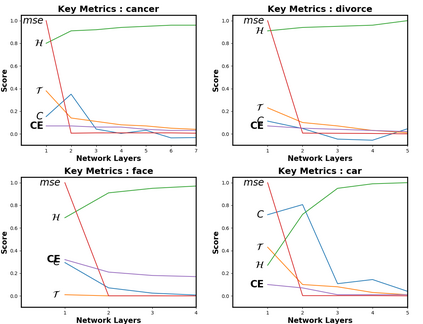
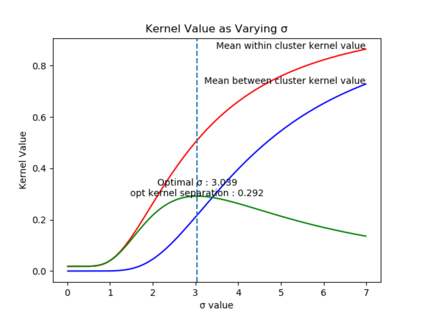
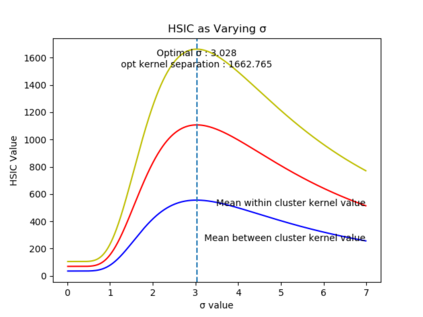
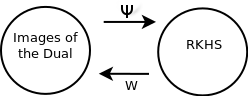
Due to recent debate over the biological plausibility of backpropagation (BP), finding an alternative network optimization strategy has become an active area of interest. We design a new type of kernel network, that is solved greedily, to theoretically answer several questions of interest. First, if BP is difficult to simulate in the brain, are there instead "trivial network weights" (requiring minimum computation) that allow a greedily trained network to classify any pattern. Perhaps a simple repetition of some basic rule can yield a network equally powerful as ones trained by BP with Stochastic Gradient Descent (SGD). Second, can a greedily trained network converge to a kernel? What kernel will it converge to? Third, is this trivial solution optimal? How is the optimal solution related to generalization? Lastly, can we theoretically identify the network width and depth without a grid search? We prove that the kernel embedding is the trivial solution that compels the greedy procedure to converge to a kernel with Universal property. Yet, this trivial solution is not even optimal. By obtaining the optimal solution spectrally, it provides insight into the generalization of the network while informing us of the network width and depth.
翻译:由于最近关于反向偏转(BBP)的生物概率的辩论,寻找替代网络优化战略已成为一个活跃的兴趣领域。我们设计了新型的内核网络,这种网络被贪婪地解决,从理论上回答几个感兴趣的问题。首先,如果BP在大脑中难以模拟,那么是否有“三重网络重量”(需要最低计算)来允许一个经过贪婪训练的网络来分类任何模式?也许简单重复一些基本规则可以产生一个与BP在Stochatic Gradient Egent Ground (SGD) 培训的网络同样强大的网络。第二,一个贪婪的训练有素的网络能够聚集到一个核心网络吗?它会聚集到什么?第三,这个微小的解决方案是最佳的吗?如何最佳的解决方案与概括化有关?最后,我们能否在理论上确定网络的宽度和深度而不进行网格搜索?我们证明内核嵌入是一个微不足道的解决方案,迫使贪婪的程序与世界性地产(SG)相融合。然而,这种微不足道的解决办法甚至并不理想。通过光谱截的解决方案,通过获得最佳的解决方案使我们了解网络的深度了解整个网络。