
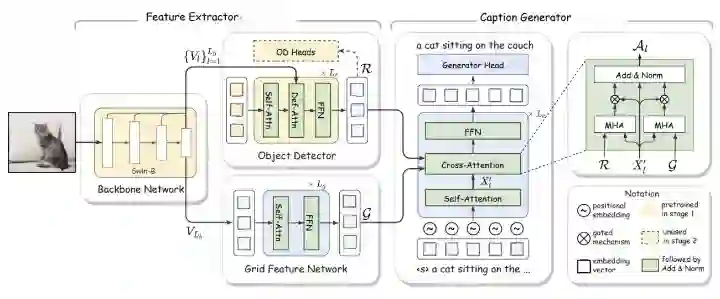
This work presents the early development of a model of image captioning for the Brazilian Portuguese language. We used the GRIT (Grid - and Region-based Image captioning Transformer) model to accomplish this work. GRIT is a Transformer-only neural architecture that effectively utilizes two visual features to generate better captions. The GRIT method emerged as a proposal to be a more efficient way to generate image captioning. In this work, we adapt the GRIT model to be trained in a Brazilian Portuguese dataset to have an image captioning method for the Brazilian Portuguese Language.
翻译:暂无翻译



相关内容
专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日
Arxiv
0+阅读 · 2024年3月19日
Arxiv
0+阅读 · 2024年3月18日


相关VIP内容
专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日
相关资讯