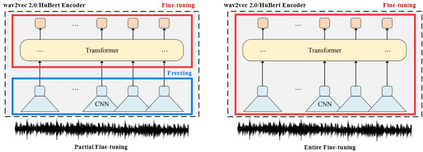
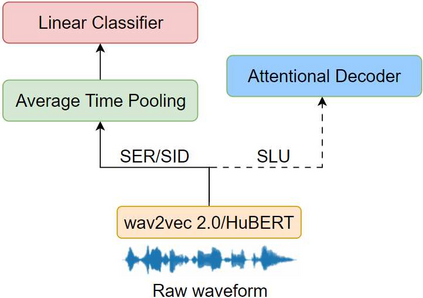
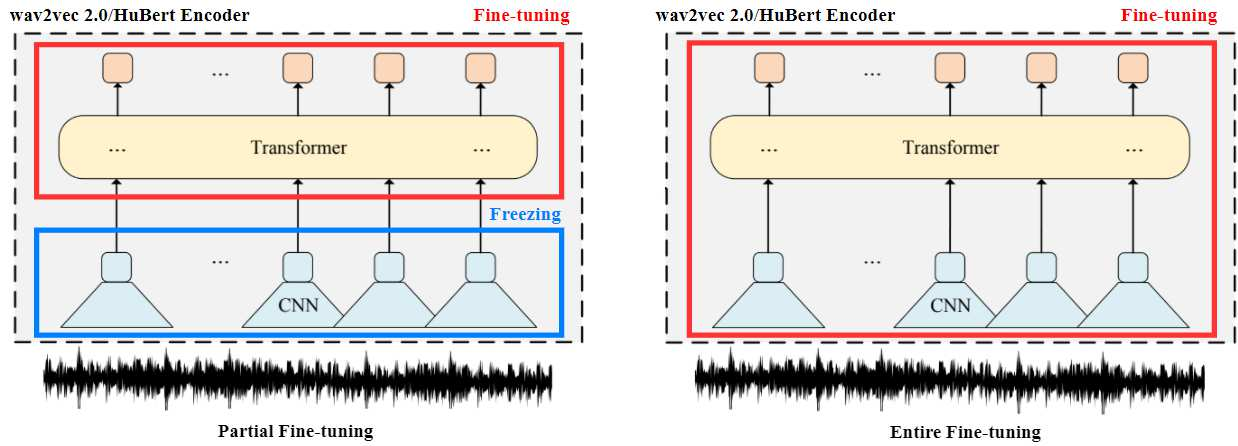
Self-supervised speech representations such as wav2vec 2.0 and HuBERT are making revolutionary progress in Automatic Speech Recognition (ASR). However, self-supervised models have not been totally proved to produce better performance on tasks other than ASR. In this work, we explore partial fine-tuning and entire fine-tuning on wav2vec 2.0 and HuBERT pre-trained models for three non-ASR speech tasks : Speech Emotion Recognition, Speaker Verification and Spoken Language Understanding. We also compare pre-trained models with/without ASR fine-tuning. With simple down-stream frameworks, the best scores reach 79.58% weighted accuracy for Speech Emotion Recognition on IEMOCAP, 2.36% equal error rate for Speaker Verification on VoxCeleb1, 87.51% accuracy for Intent Classification and 75.32% F1 for Slot Filling on SLURP, thus setting a new state-of-the-art for these three benchmarks, proving that fine-tuned wav2vec 2.0 and HuBERT models can better learn prosodic, voice-print and semantic representations.
翻译:在这项工作中,我们探索了对Wav2vec2.0和HuBERT三个非ASR演讲任务进行部分微调和整个微调的方法,这三个非ASR演讲任务为:语音情感识别、发言人核查和口头语言理解。我们还比较了预先培训的模型和/没有ASR微调的模型。通过简单的下流框架,自我监督的模型的最佳得分达到IEMOCAP语音识别加权精度的79.58%, VoxCeleb1、87.51% Inted分类发言人核查的精度相等的2.36%,SLURP Slot填充的精度为75.32% F1,从而为这三项基准设定了新的最新技术,证明微调的 wav2vec 2.0和HuBERT 模型可以更好地学习Prosodic、语音和语义表达。