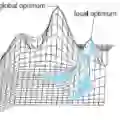
Instead of building deep learning models from scratch, developers are more and more relying on adapting pre-trained models to their customized tasks. However, powerful pre-trained models may be misused for unethical or illegal tasks, e.g., privacy inference and unsafe content generation. In this paper, we introduce a pioneering learning paradigm, non-fine-tunable learning, which prevents the pre-trained model from being fine-tuned to indecent tasks while preserving its performance on the original task. To fulfill this goal, we propose SOPHON, a protection framework that reinforces a given pre-trained model to be resistant to being fine-tuned in pre-defined restricted domains. Nonetheless, this is challenging due to a diversity of complicated fine-tuning strategies that may be adopted by adversaries. Inspired by model-agnostic meta-learning, we overcome this difficulty by designing sophisticated fine-tuning simulation and fine-tuning evaluation algorithms. In addition, we carefully design the optimization process to entrap the pre-trained model within a hard-to-escape local optimum regarding restricted domains. We have conducted extensive experiments on two deep learning modes (classification and generation), seven restricted domains, and six model architectures to verify the effectiveness of SOPHON. Experiment results verify that fine-tuning SOPHON-protected models incurs an overhead comparable to or even greater than training from scratch. Furthermore, we confirm the robustness of SOPHON to three fine-tuning methods, five optimizers, various learning rates and batch sizes. SOPHON may help boost further investigations into safe and responsible AI.
翻译:暂无翻译