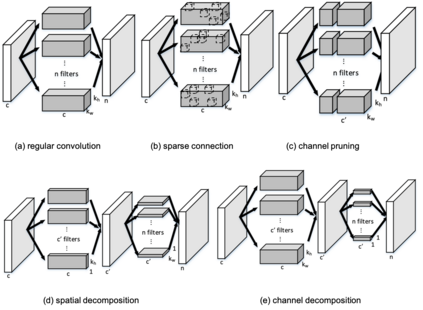
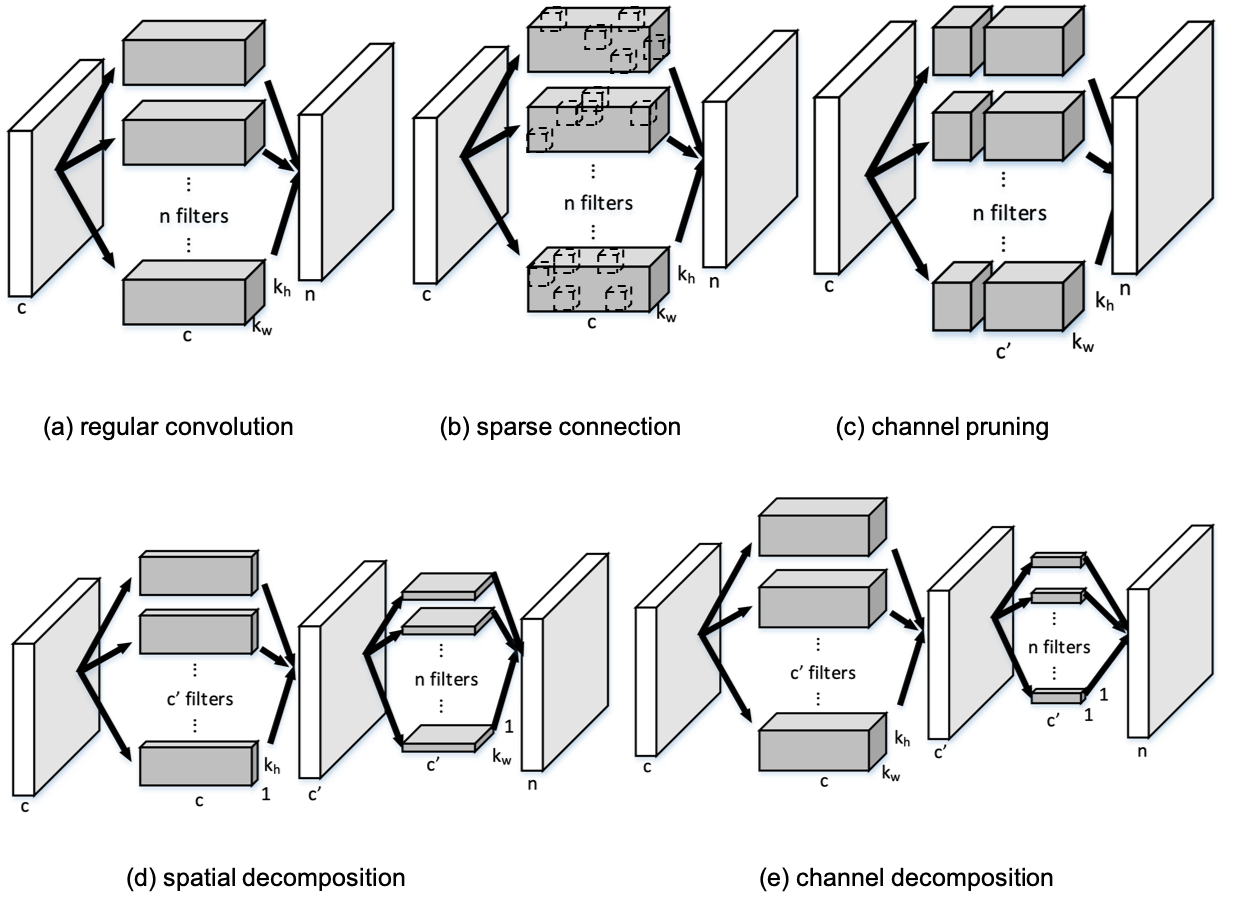
Very deep convolutional neural networks (CNNs) have been firmly established as the primary methods for many computer vision tasks. However, most state-of-the-art CNNs are large, which results in high inference latency. Recently, depth-wise separable convolution has been proposed for image recognition tasks on computationally limited platforms such as robotics and self-driving cars. Though it is much faster than its counterpart, regular convolution, accuracy is sacrificed. In this paper, we propose a novel decomposition approach based on SVD, namely depth-wise decomposition, for expanding regular convolutions into depthwise separable convolutions while maintaining high accuracy. We show our approach can be further generalized to the multi-channel and multi-layer cases, based on Generalized Singular Value Decomposition (GSVD) [59]. We conduct thorough experiments with the latest ShuffleNet V2 model [47] on both random synthesized dataset and a large-scale image recognition dataset: ImageNet [10]. Our approach outperforms channel decomposition [73] on all datasets. More importantly, our approach improves the Top-1 accuracy of ShuffleNet V2 by ~2%.
翻译:非常深层的神经神经网络(CNNs)已被牢固地确定为许多计算机视觉任务的主要方法。然而,大多数最先进的CNN是大型的,导致高推力延缓。最近,在计算上有限的平台(如机器人和自驾驶汽车)的图像识别任务中,提出了深度分解的共变建议。虽然比其对应平台要快得多,但通常的共振还是牺牲了准确性。在本文中,我们提议了一种基于SVD的新式分解方法,即深度-明智分解,将常规的共振扩大为深度的分解,同时保持高精确度。我们展示了我们的方法可以进一步推广到多频道和多层案例,基于通用的Singulal 值分解(GSVD) [599]。我们用最新的ShuffleNet V2 [477] 模型对随机合成数据集和大型图像识别数据集(图像网)进行彻底的实验:图像网 [10] 。我们的方法超越了所有数据集精确度-% Top 的系统- 改进了我们的方法。