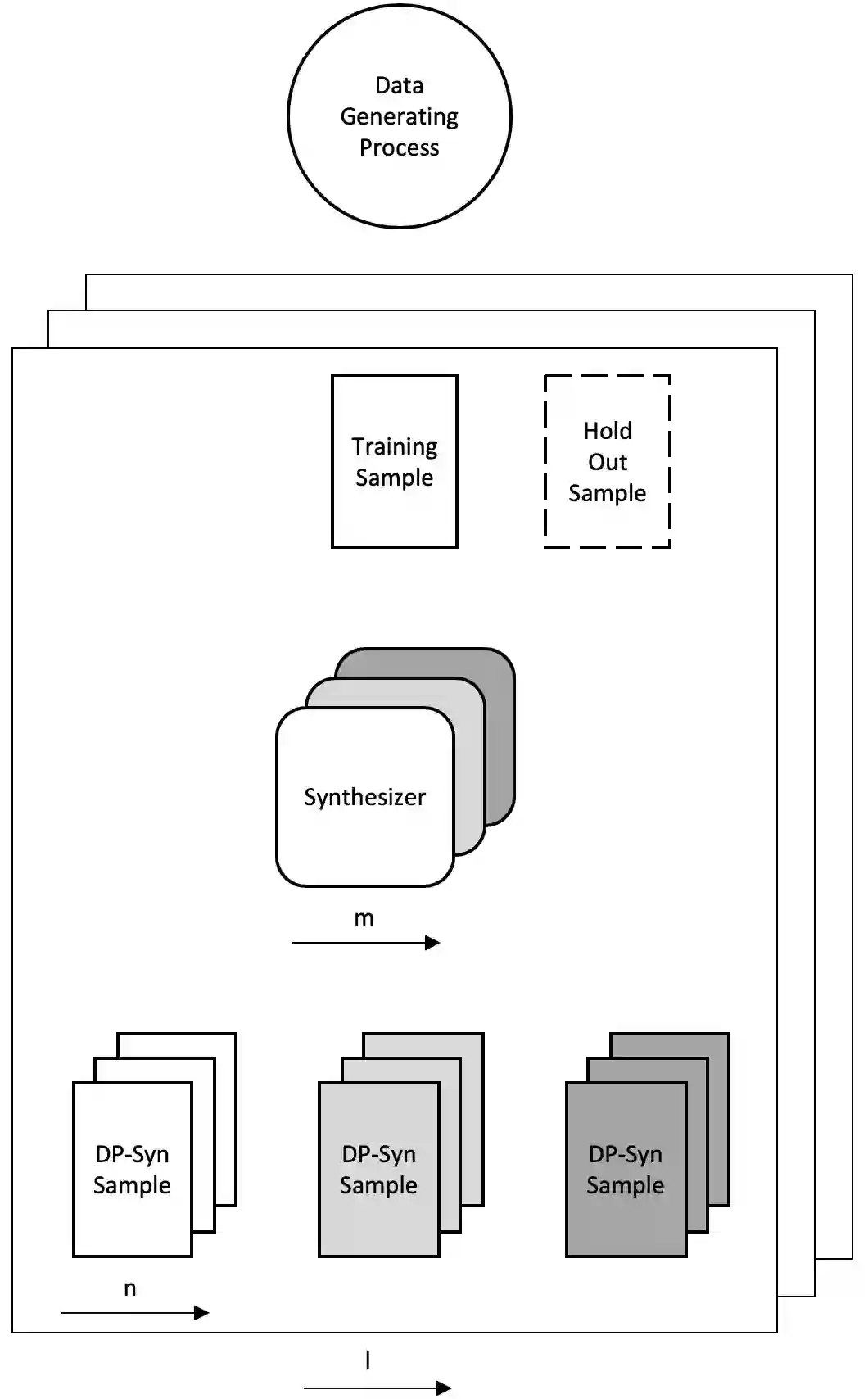
Recent advances in generating synthetic data that allow to add principled ways of protecting privacy -- such as Differential Privacy -- are a crucial step in sharing statistical information in a privacy preserving way. But while the focus has been on privacy guarantees, the resulting private synthetic data is only useful if it still carries statistical information from the original data. To further optimise the inherent trade-off between data privacy and data quality, it is necessary to think closely about the latter. What is it that data analysts want? Acknowledging that data quality is a subjective concept, we develop a framework to evaluate the quality of differentially private synthetic data from an applied researcher's perspective. Data quality can be measured along two dimensions. First, quality of synthetic data can be evaluated against training data or against an underlying population. Second, the quality of synthetic data depends on general similarity of distributions or specific tasks such as inference or prediction. It is clear that accommodating all goals at once is a formidable challenge. We invite the academic community to jointly advance the privacy-quality frontier.
翻译:在生成能够增加保护隐私的原则性方法的合成数据方面最近取得的进展,如不同隐私等,是以隐私保护方式分享统计信息的关键步骤。虽然重点是隐私保障,但由此产生的私人合成数据只有在仍然从原始数据中提供统计信息的情况下才有用。为了进一步优化数据隐私与数据质量之间的内在权衡,有必要仔细考虑后者。数据分析员想要的是后者什么?认识到数据质量是一个主观概念,我们制定了一个框架,从应用研究人员的角度评价差异性私人合成数据的质量。数据质量可以从两个方面来衡量。首先,合成数据的质量可以根据培训数据或根据基础人口来评估。第二,合成数据的质量取决于分布的一般相似性或具体任务,例如推论或预测。很明显,立即兼顾所有目标是一个艰巨的挑战。我们请学术界共同推进隐私质量的前沿。