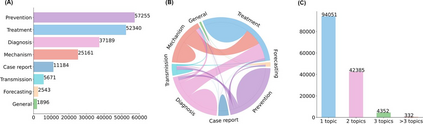
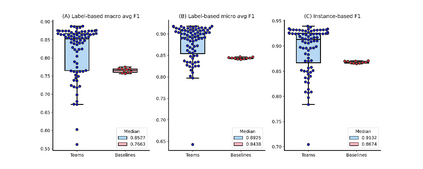
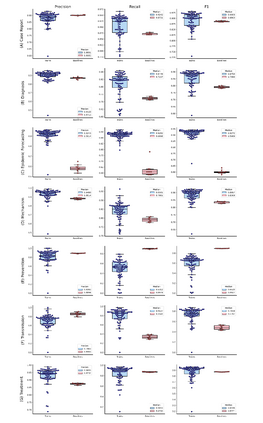
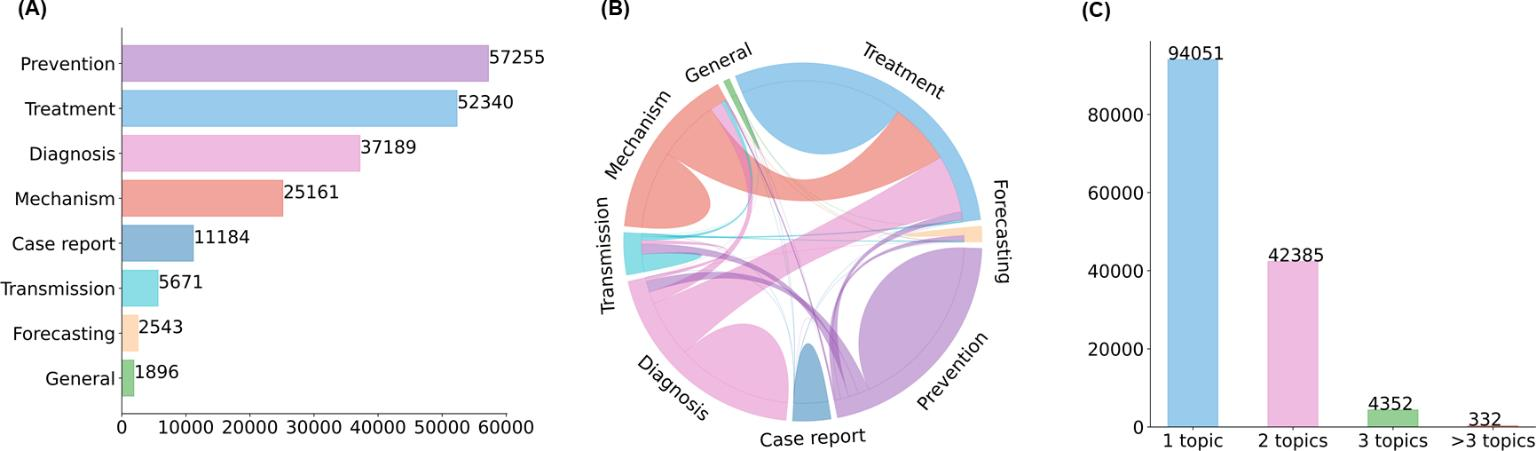
The COVID-19 pandemic has been severely impacting global society since December 2019. Massive research has been undertaken to understand the characteristics of the virus and design vaccines and drugs. The related findings have been reported in biomedical literature at a rate of about 10,000 articles on COVID-19 per month. Such rapid growth significantly challenges manual curation and interpretation. For instance, LitCovid is a literature database of COVID-19-related articles in PubMed, which has accumulated more than 200,000 articles with millions of accesses each month by users worldwide. One primary curation task is to assign up to eight topics (e.g., Diagnosis and Treatment) to the articles in LitCovid. Despite the continuing advances in biomedical text mining methods, few have been dedicated to topic annotations in COVID-19 literature. To close the gap, we organized the BioCreative LitCovid track to call for a community effort to tackle automated topic annotation for COVID-19 literature. The BioCreative LitCovid dataset, consisting of over 30,000 articles with manually reviewed topics, was created for training and testing. It is one of the largest multilabel classification datasets in biomedical scientific literature. 19 teams worldwide participated and made 80 submissions in total. Most teams used hybrid systems based on transformers. The highest performing submissions achieved 0.8875, 0.9181, and 0.9394 for macro F1-score, micro F1-score, and instance-based F1-score, respectively. The level of participation and results demonstrate a successful track and help close the gap between dataset curation and method development. The dataset is publicly available via https://ftp.ncbi.nlm.nih.gov/pub/lu/LitCovid/biocreative/ for benchmarking and further development.
翻译:自2019年12月以来,COVID-19大流行严重影响了全球社会; 开展了大规模研究,以了解病毒的特征并设计疫苗和药物; 生物医学文献中报告的相关研究结果每月约10 000篇关于COVID-19的文章; 这种快速增长对人工校正和解释提出了重大挑战; 例如,LitCovid是PubMed中COVID-19相关文章的文献数据库,全世界用户每月有数百万次访问,该数据库积累了200 000多篇文章; 一项首要任务是为LitCovid的文章分配多达8个专题(如诊断和治疗)。 尽管生物医学文本采矿方法不断进步,但很少专门用于COVID-19文学的专题说明。 为弥补这一差距,我们组织了BiocreativeLitCovid轨道,呼吁社区努力解决COVID-19文献的自动化专题。 BioCretaliveLickd数据集包括30 000多篇经过手动审查的专题的帮助, 用于培训和测试。