
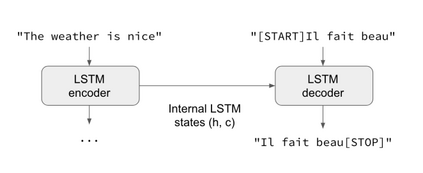
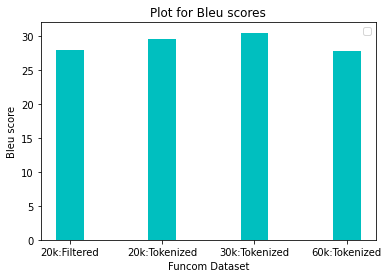
Code summarization is the task of generating readable summaries that are semantically meaningful and can accurately describe the presumed task of a software. Program comprehension has become one of the most tedious tasks for knowledge transfer. As the codebase evolves over time, the description needs to be manually updated each time with the changes made. An automatic approach is proposed to infer such captions based on benchmarked and custom datasets with comparison between the original and generated results.
翻译:代码总和是生成可读摘要的任务,这些摘要具有语义意义,能够准确描述软件的假定任务。程序理解已成为知识转让最繁琐的任务之一。随着代码库的演变,每次需要随着修改而手工更新描述。建议采用自动办法,根据基准和定制数据集来推断这些标题,比较原始和生成的结果。


相关内容

一个旨在提升互联网阅读体验的工具。
http://readability.com/
相关主题




相关VIP内容
相关资讯
相关论文