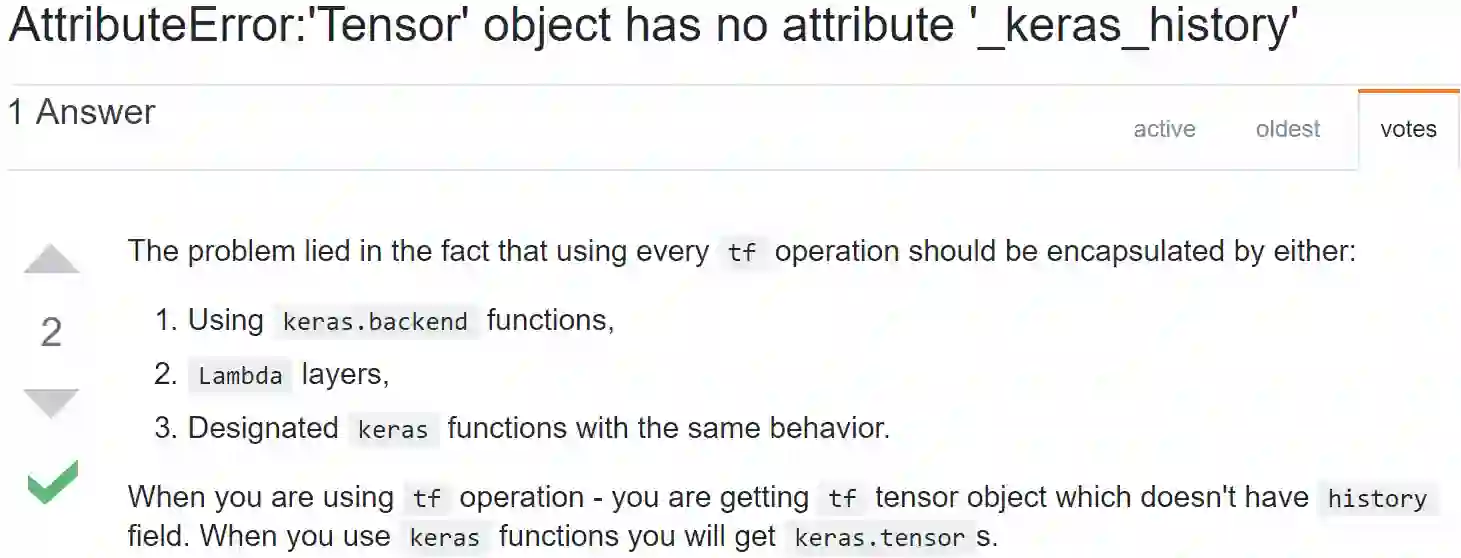
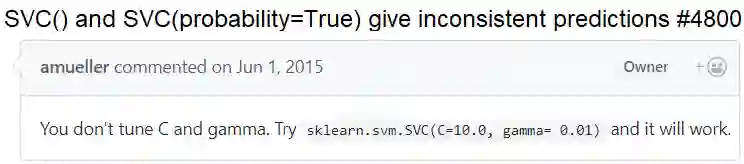
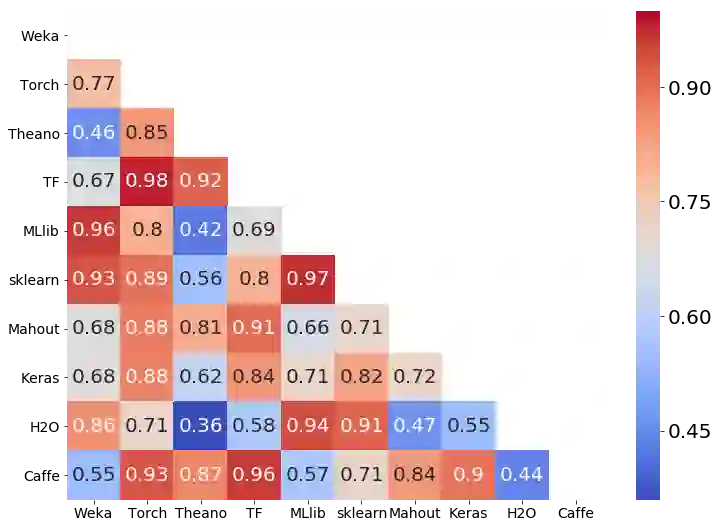
Modern software systems are increasingly including machine learning (ML) as an integral component. However, we do not yet understand the difficulties faced by software developers when learning about ML libraries and using them within their systems. To that end, this work reports on a detailed (manual) examination of 3,243 highly-rated Q&A posts related to ten ML libraries, namely Tensorflow, Keras, scikit-learn, Weka, Caffe, Theano, MLlib, Torch, Mahout, and H2O, on Stack Overflow, a popular online technical Q&A forum. We classify these questions into seven typical stages of an ML pipeline to understand the correlation between the library and the stage. Then we study the questions and perform statistical analysis to explore the answer to four research objectives (finding the most difficult stage, understanding the nature of problems, nature of libraries and studying whether the difficulties stayed consistent over time). Our findings reveal the urgent need for software engineering (SE) research in this area. Both static and dynamic analyses are mostly absent and badly needed to help developers find errors earlier. While there has been some early research on debugging, much more work is needed. API misuses are prevalent and API design improvements are sorely needed. Last and somewhat surprisingly, a tug of war between providing higher levels of abstractions and the need to understand the behavior of the trained model is prevalent.
翻译:现代软件系统越来越多地将机器学习(ML)作为一个有机组成部分。然而,我们尚不理解软件开发者在学习ML图书馆和使用这些图书馆时所面临的困难。为此,本工作报告对10个ML图书馆的3,243个高度评级的 ⁇ A 员额(即Tensorflow、Keras、Scikit-learn、Weka、Cafe、Theano、MLlib、Torch、Mahout和H2O)进行详细(手工)审查,以了解ML图书馆和使用图书馆时所面临的困难。我们将这些问题纳入ML管道的七个典型阶段,以了解图书馆与该阶段之间的相互关系。然后我们研究这些问题并进行统计分析,以探讨对四个研究目标(即Tensorflow、Keras、Sikit-learn、Wek、Caf、Cafeffe、Thefer、Theano、MLlib、Torch、Mahout和H2O)的答案。我们的调查结果显示,迫切需要在这一领域进行软件工程模型研究。静态和动态分析,以助开发者更早发现错误。我们需要先行。对惯性的行为进行早期的改进。虽然已经对惯性研究,但对惯用性研究需要更深地研订,但需要更深地研究需要更深地进行深地研究。