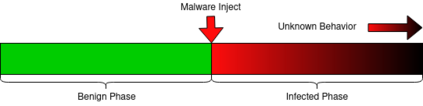
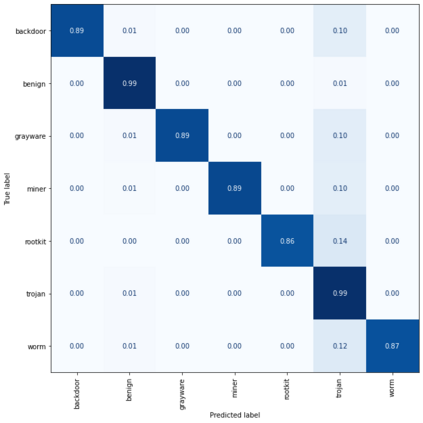
Accurately classifying malware in an environment allows the creation of better response and remediation strategies by cyber analysts. However, classifying malware in a live environment is a difficult task due to the large number of system data sources. Collecting statistics from these separate sources and processing them together in a form that can be used by a machine learning model is difficult. Fortunately, all of these resources are mediated by the operating system's kernel. User programs, malware included, interacts with system resources by making requests to the kernel with system calls. Collecting these system calls provide insight to the interaction with many system resources in a single location. Feeding these system calls into a performant model such as a random forest allows fast, accurate classification in certain situations. In this paper, we evaluate the feasibility of using system call sequences for online malware classification in both low-activity and heavy-use Cloud IaaS. We collect system calls as they are received by the kernel and take n-gram sequences of calls to use as features for tree-based machine learning models. We discuss the performance of the models on baseline systems with no extra running services and systems under heavy load and the performance gap between them.
翻译:对环境中的恶意软件进行准确分类,可以使网络分析人员制定更好的反应和补救战略。然而,由于系统数据来源众多,在现场环境中对恶意软件进行分类是一项艰巨的任务。从这些不同的来源收集统计数据,并用机器学习模式可以使用的形式一起处理这些数据是困难的。幸运的是,所有这些资源都由操作系统的内核来调解。用户程序、包括恶意软件,通过向内核发出系统呼叫与系统资源进行互动。收集这些系统电话为与单一地点的许多系统资源的互动提供洞察力。将这些系统连接成一个性能模型,例如随机森林,在某些情况下可以快速、准确地分类。在本文件中,我们评估使用系统呼叫序列对低活性和重用云IaaS进行在线恶意软件分类的可行性。我们从内核收到系统电话时收集系统电话,并采用n-gram的通话顺序作为树基学习模型的特征。我们讨论了基线系统模型的性能,没有额外运行服务,也没有在重负载系统下进行功能差距和重载系统。