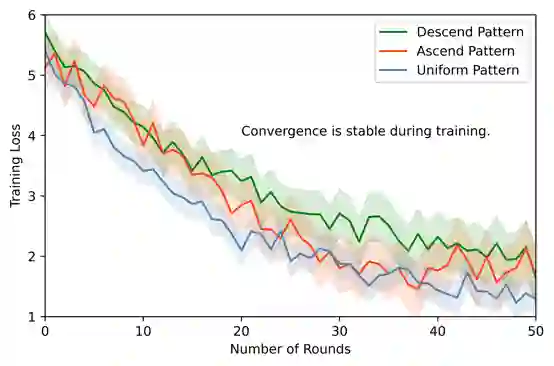
Large vision-language models (VLMs) often benefit from intermediate visual cues, either injected via external tools or generated as latent visual tokens during reasoning, but these mechanisms still overlook fine-grained visual evidence (e.g., polylines in charts), generalize poorly across domains, and incur high inference-time cost. In this paper, we propose Bi-directional Perceptual Shaping (BiPS), which transforms question-conditioned masked views into bidirectional where-to-look signals that shape perception during training. BiPS first applies a KL-consistency constraint between the original image and an evidence-preserving view that keeps only question-relevant regions, encouraging coarse but complete coverage of supporting pixels. It then applies a KL-separation constraint between the original and an evidence-ablated view where critical pixels are masked so the image no longer supports the original answer, discouraging text-only shortcuts (i.e., answering from text alone) and enforcing fine-grained visual reliance. Across eight benchmarks, BiPS boosts Qwen2.5-VL-7B by 8.2% on average and shows strong out-of-domain generalization to unseen datasets and image types.
翻译:大型视觉语言模型(VLMs)通常受益于中间视觉线索,这些线索通过外部工具注入或在推理过程中生成为潜在视觉标记,但这些机制仍忽略了细粒度视觉证据(如图表中的折线),跨领域泛化能力较差,且推理时成本高昂。本文提出双向感知塑形(BiPS),该方法将问题条件化的掩码视图转化为双向的“看向何处”信号,在训练过程中塑造感知。BiPS首先在原始图像与仅保留问题相关区域的证据保留视图之间施加KL一致性约束,鼓励对支持像素进行粗略但完整的覆盖。随后,在原始图像与证据消除视图之间施加KL分离约束,其中关键像素被掩码,使得图像不再支持原始答案,从而抑制纯文本捷径(即仅从文本作答)并强制模型依赖细粒度视觉信息。在八个基准测试中,BiPS将Qwen2.5-VL-7B的平均性能提升了8.2%,并在未见数据集和图像类型上展现出强大的跨领域泛化能力。