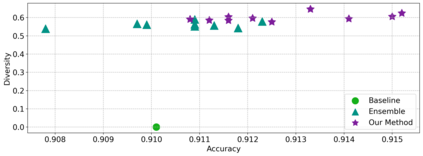
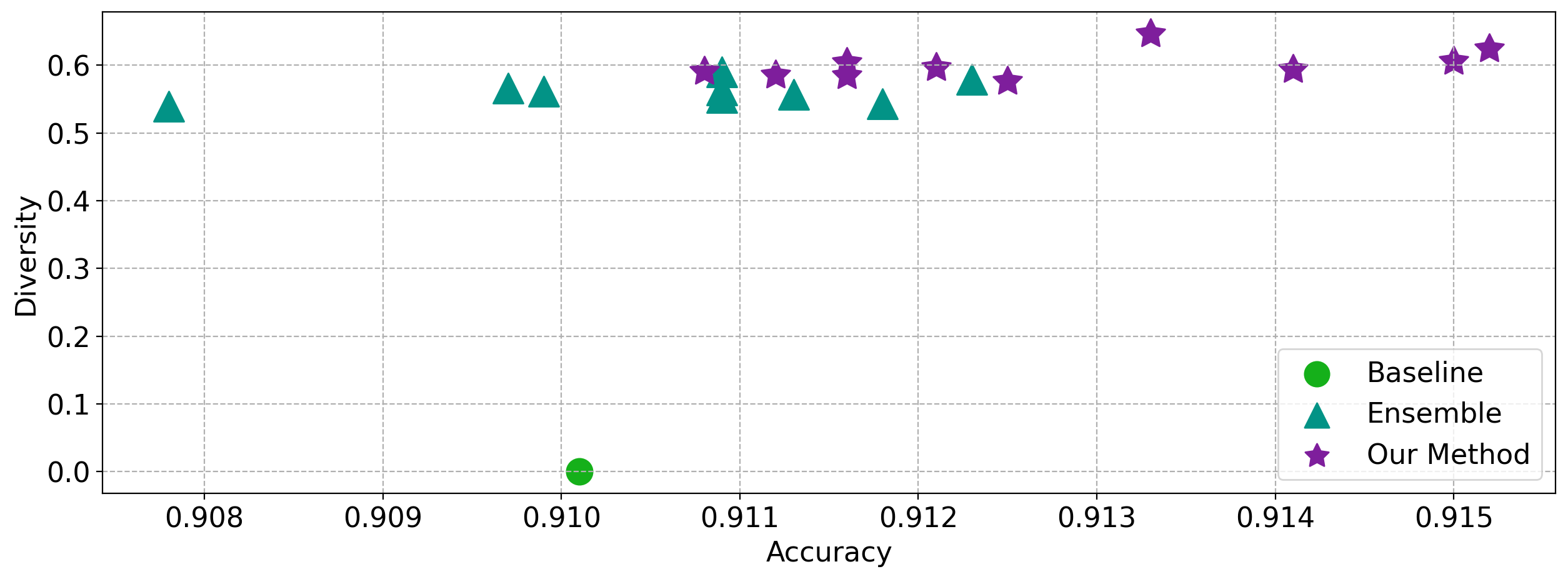
Ensembling a neural network is a widely recognized approach to enhance model performance, estimate uncertainty, and improve robustness in deep supervised learning. However, deep ensembles often come with high computational costs and memory demands. In addition, the efficiency of a deep ensemble is related to diversity among the ensemble members which is challenging for large, over-parameterized deep neural networks. Moreover, ensemble learning has not yet seen such widespread adoption, and it remains a challenging endeavor for self-supervised or unsupervised representation learning. Motivated by these challenges, we present a novel self-supervised training regime that leverages an ensemble of independent sub-networks, complemented by a new loss function designed to encourage diversity. Our method efficiently builds a sub-model ensemble with high diversity, leading to well-calibrated estimates of model uncertainty, all achieved with minimal computational overhead compared to traditional deep self-supervised ensembles. To evaluate the effectiveness of our approach, we conducted extensive experiments across various tasks, including in-distribution generalization, out-of-distribution detection, dataset corruption, and semi-supervised settings. The results demonstrate that our method significantly improves prediction reliability. Our approach not only achieves excellent accuracy but also enhances calibration, surpassing baseline performance across a wide range of self-supervised architectures in computer vision, natural language processing, and genomics data.
翻译:暂无翻译