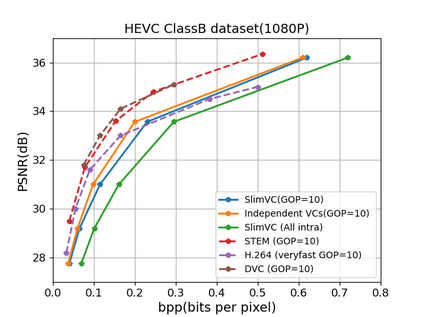
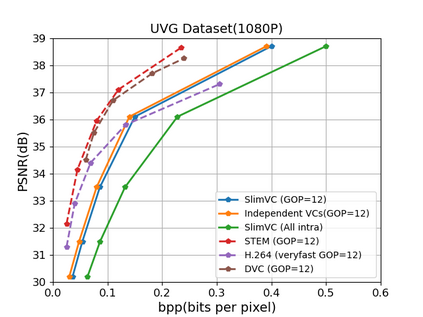
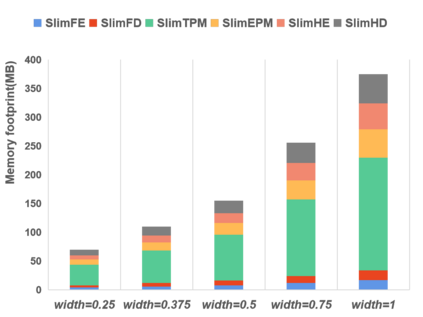
Neural video compression has emerged as a novel paradigm combining trainable multilayer neural networks and machine learning, achieving competitive rate-distortion (RD) performances, but still remaining impractical due to heavy neural architectures, with large memory and computational demands. In addition, models are usually optimized for a single RD tradeoff. Recent slimmable image codecs can dynamically adjust their model capacity to gracefully reduce the memory and computation requirements, without harming RD performance. In this paper we propose a slimmable video codec (SlimVC), by integrating a slimmable temporal entropy model in a slimmable autoencoder. Despite a significantly more complex architecture, we show that slimming remains a powerful mechanism to control rate, memory footprint, computational cost and latency, all being important requirements for practical video compression.
翻译:神经视频压缩已成为一种新型范例,结合了可训练的多层神经网络和机器学习,实现了具有竞争力的电率扭曲性(RD)性能,但由于神经结构繁重,内存和计算需求巨大,仍然不切实际。此外,模型通常被优化用于一次RD交换。最近微薄的图像解码器可以动态调整模型能力,以优美地减少记忆和计算要求,而不会损害RD的性能。在本文中,我们提出一个微薄的视频编码器(SlimVC ), 将一个微薄的时温模型整合到一个微薄的自动编码器中。 尽管一个复杂得多的架构,但我们显示瘦化仍然是控制速率、记忆足迹、计算成本和耐久度的强大机制,所有这些都是实用视频压缩的重要要求。