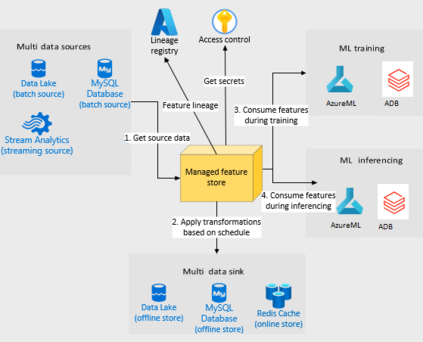
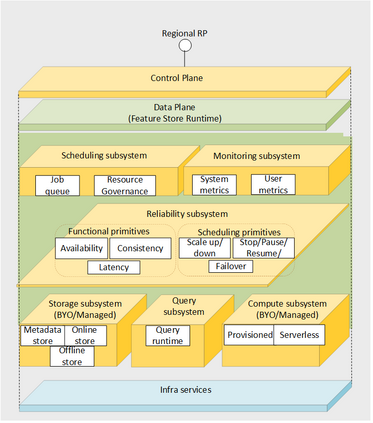
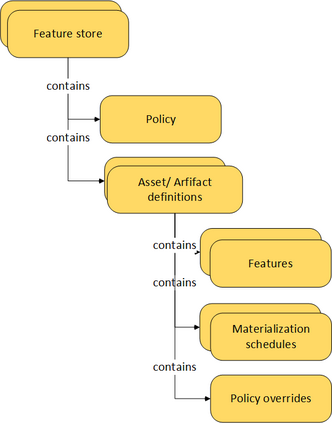
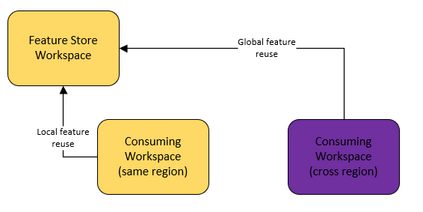
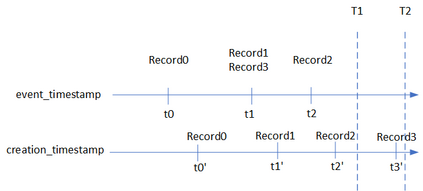
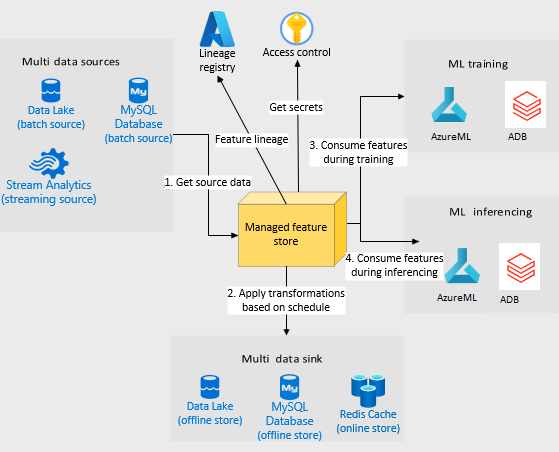
Companies are using machine learning to solve real-world problems and are developing hundreds to thousands of features in the process. They are building feature engineering pipelines as part of MLOps life cycle to transform data from various data sources and materialize the same for future consumption. Without feature stores, different teams across various business groups would maintain the above process independently, which can lead to conflicting and duplicated features in the system. Data scientists find it hard to search for and reuse existing features and it is painful to maintain version control. Furthermore, feature correctness violations related to online (inferencing) - offline (training) skews and data leakage are common. Although the machine learning community has extensively discussed the need for feature stores and their purpose, this paper aims to capture the core architectural components that make up a managed feature store and to share the design learning in building such a system.
翻译:暂无翻译