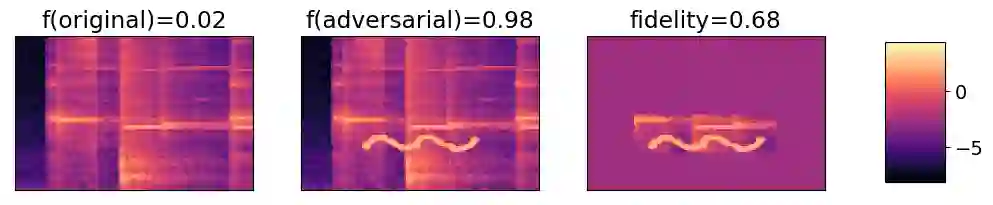
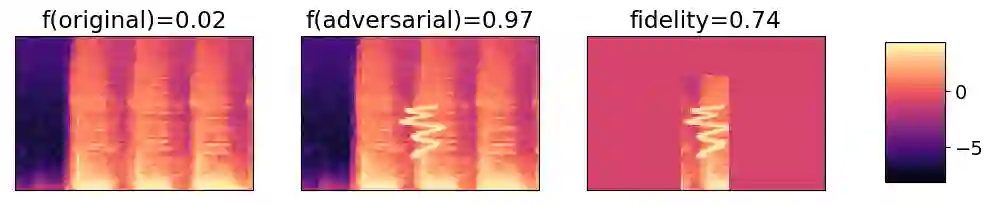
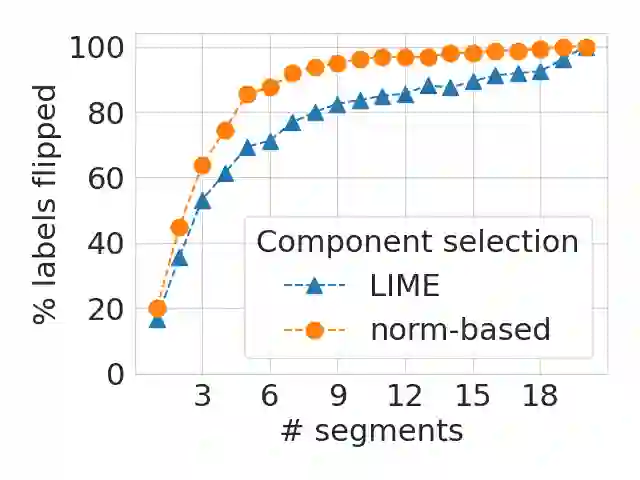
Local explanation methods such as LIME have become popular in MIR as tools for generating post-hoc, model-agnostic explanations of a model's classification decisions. The basic idea is to identify a small set of human-understandable features of the classified example that are most influential on the classifier's prediction. These are then presented as an explanation. Evaluation of such explanations in publications often resorts to accepting what matches the expectation of a human without actually being able to verify if what the explanation shows is what really caused the model's prediction. This paper reports on targeted investigations where we try to get more insight into the actual veracity of LIME's explanations in an audio classification task. We deliberately design adversarial examples for the classifier, in a way that gives us knowledge about which parts of the input are potentially responsible for the model's (wrong) prediction. Asking LIME to explain the predictions for these adversaries permits us to study whether local explanations do indeed detect these regions of interest. We also look at whether LIME is more successful in finding perturbations that are more prominent and easily noticeable for a human. Our results suggest that LIME does not necessarily manage to identify the most relevant input features and hence it remains unclear whether explanations are useful or even misleading.
翻译:LIME 等本地解释方法在MIR 中成为流行,作为生成模型分类决定的后热解、模型-不可知解释的工具。基本想法是确定对分类者预测最有影响力的分类示例中一小组可理解的人类特征。然后将这些解释作为解释加以介绍。在出版物中对此类解释的评价往往以接受与人类期望相符的内容为手段,而实际上又无法核实解释所显示的内容是否真正导致模型的预测。本文报告了有针对性的调查,我们试图在音频分类任务中更深入了解LIME解释的真实性。我们有意为分类者设计对抗性实例,以使我们了解哪些部分投入可能对模型(错误的)预测负责。请LIME解释这些对手的预测,使我们可以研究当地解释是否确实检测了这些感兴趣的区域。我们还研究了LIME是否更成功地找到对人类来说更突出、更易察觉的深层次点。我们的结果表明,LIME的解释是否具有最不明确的特性,是否因此无法很好地识别。