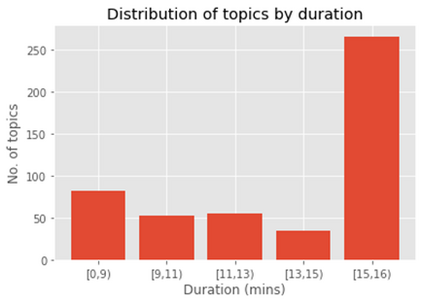
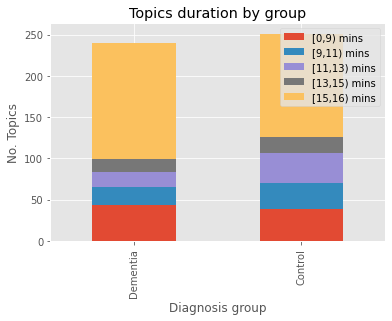
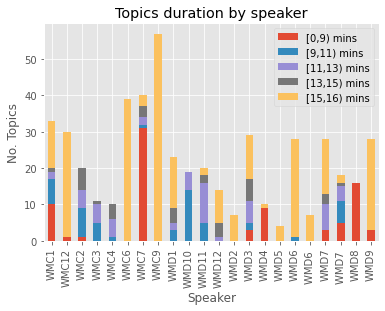
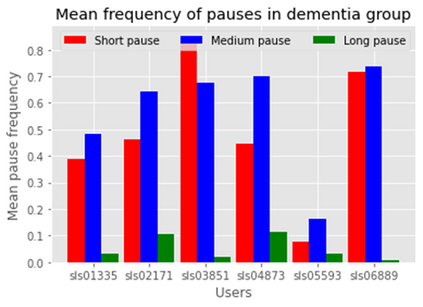
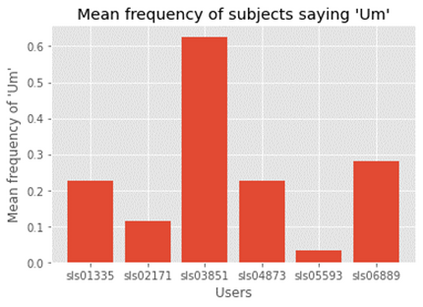
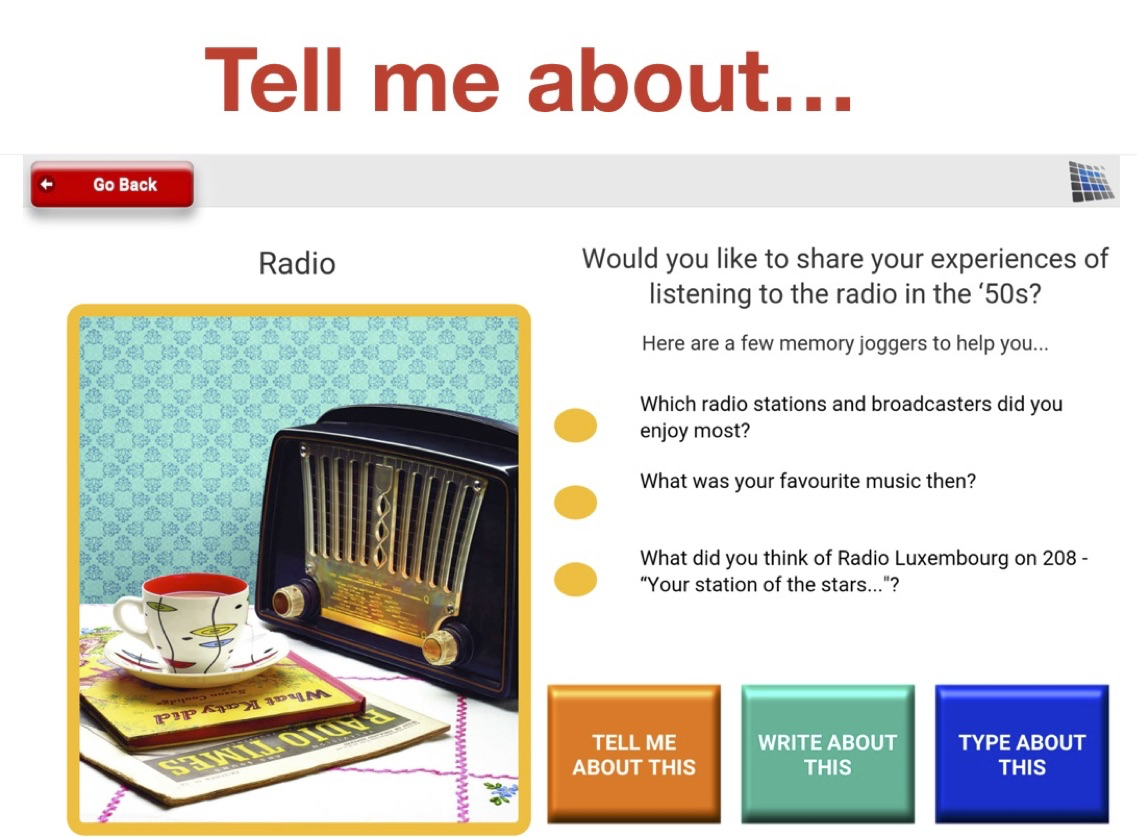
Dementia is a family of neurogenerative conditions affecting memory and cognition in an increasing number of individuals in our globally aging population. Automated analysis of language, speech and paralinguistic indicators have been gaining popularity as potential indicators of cognitive decline. Here we propose a novel longitudinal multi-modal dataset collected from people with mild dementia and age matched controls over a period of several months in a natural setting. The multi-modal data consists of spoken conversations, a subset of which are transcribed, as well as typed and written thoughts and associated extra-linguistic information such as pen strokes and keystrokes. We describe the dataset in detail and proceed to focus on a task using the speech modality. The latter involves distinguishing controls from people with dementia by exploiting the longitudinal nature of the data. Our experiments showed significant differences in how the speech varied from session to session in the control and dementia groups.
翻译:痴呆症是一个神经基因条件影响着我们全球老龄化人口中越来越多的人的记忆和认知的大家庭,对语言、语言和语言指标的自动分析越来越受欢迎,成为认知下降的潜在指标。我们在这里提议从轻微痴呆症和年龄的人那里收集的新颖的纵向多模式数据集,在自然环境中经过几个月的监控,对数据进行匹配。多模式数据包括口语对话,其中一部分是转录的,以及打字和书面思想和相关的语言外信息,如笔划和键盘。我们详细描述数据集,并开始侧重于使用语言模式执行的任务。后者涉及通过利用数据的纵向性质来区分痴呆症患者的控制措施。我们的实验显示,在控制和痴呆症群体中,语言的交替方式差异很大。