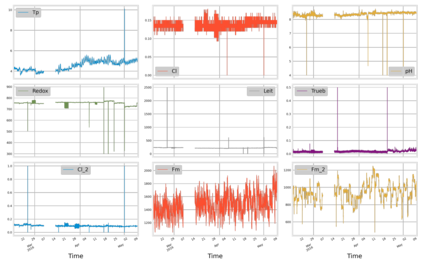
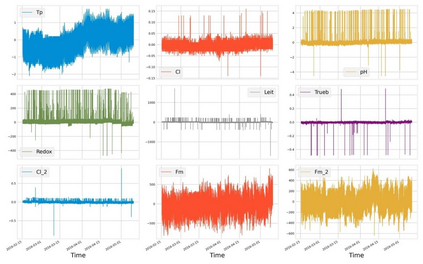
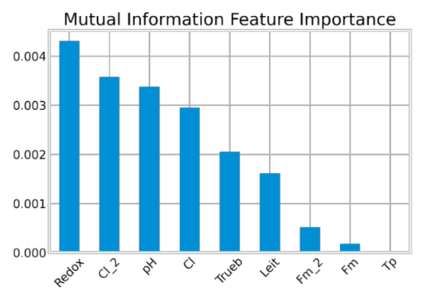
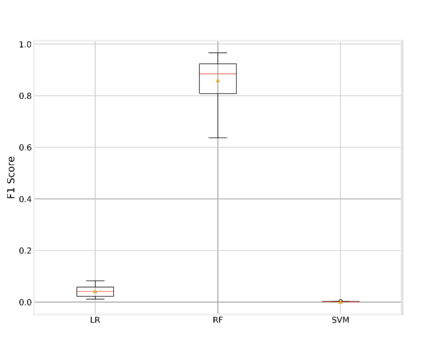
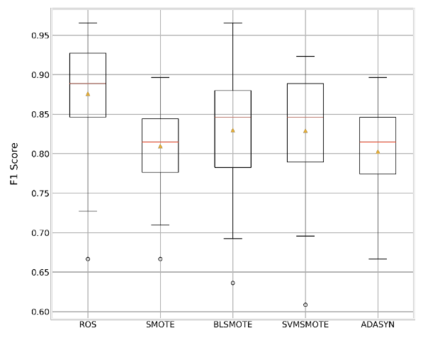
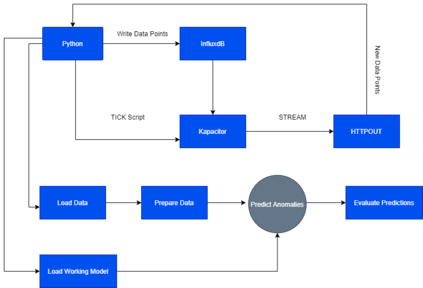
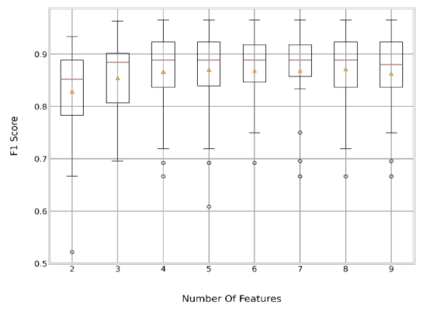
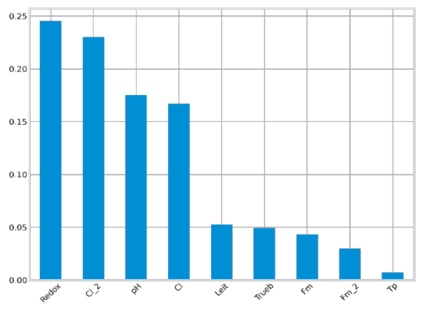
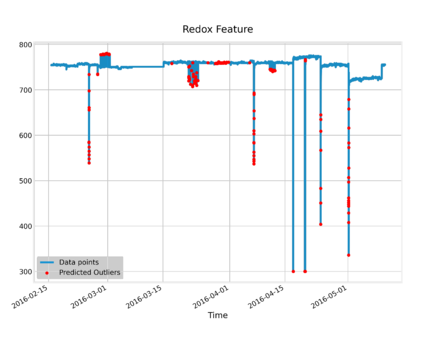
Analysis of water and environmental data is an important aspect of many intelligent water and environmental system applications where inference from such analysis plays a significant role in decision making. Quite often these data that are collected through sensible sensors can be anomalous due to different reasons such as systems breakdown, malfunctioning of sensor detectors, and more. Regardless of their root causes, such data severely affect the results of the subsequent analysis. This paper demonstrates data cleaning and preparation for time-series data and further proposes cost-sensitive machine learning algorithms as a solution to detect anomalous data points in time-series data. The following models: Logistic Regression, Random Forest, Support Vector Machines have been modified to support the cost-sensitive learning which penalizes misclassified samples thereby minimizing the total misclassification cost. Our results showed that Random Forest outperformed the rest of the models at predicting the positive class (i.e anomalies). Applying predictive model improvement techniques like data oversampling seems to provide little or no improvement to the Random Forest model. Interestingly, with recursive feature elimination, we achieved a better model performance thereby reducing the dimensions in the data. Finally, with Influxdb and Kapacitor the data was ingested and streamed to generate new data points to further evaluate the model performance on unseen data, this will allow for early recognition of undesirable changes in the drinking water quality and will enable the water supply companies to rectify on a timely basis whatever undesirable changes abound.
翻译:水和环境数据分析是许多智能水和环境系统应用的一个重要方面,从这种分析中推断出,这些数据在决策中起着重要作用。通过明智的传感器收集的这些数据,由于系统故障、传感器探测器故障等不同原因,往往可能是异常的。这些数据尽管有其根本原因,却严重影响了随后分析的结果。本文展示了数据清理和时间序列数据准备情况,并进一步提出了成本敏感的机器学习算法,作为探测时间序列数据中不正常数据点的一种解决办法。以下模型:后勤反射、随机森林、支助矢量机器已经修改,以支持成本敏感的学习,从而惩罚分类不当的样品,从而尽量减少全部分类费用。我们的结果显示,随机森林在预测正级(即异常情况)时,比模型的其余部分要差。应用预测性模型改进技术,例如多采取数据,似乎很少或根本没有改进随机森林模型。有趣的是,在时间序列数据序列中,我们取得了更好的模型性能,从而降低了数据质量的方方面面,从而降低了数据质量。最后,随机数据将使得模型的性能进一步产生数据。