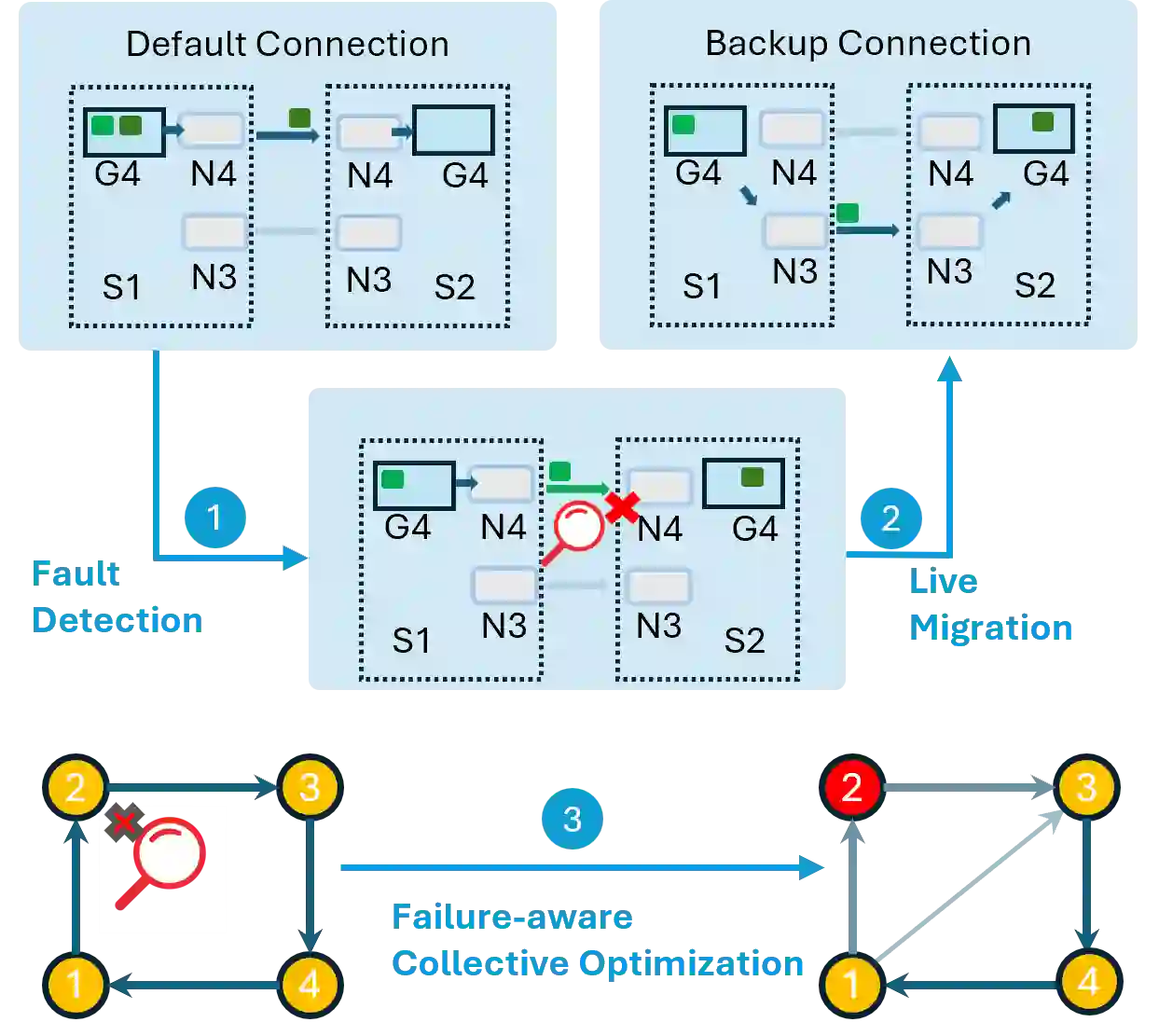
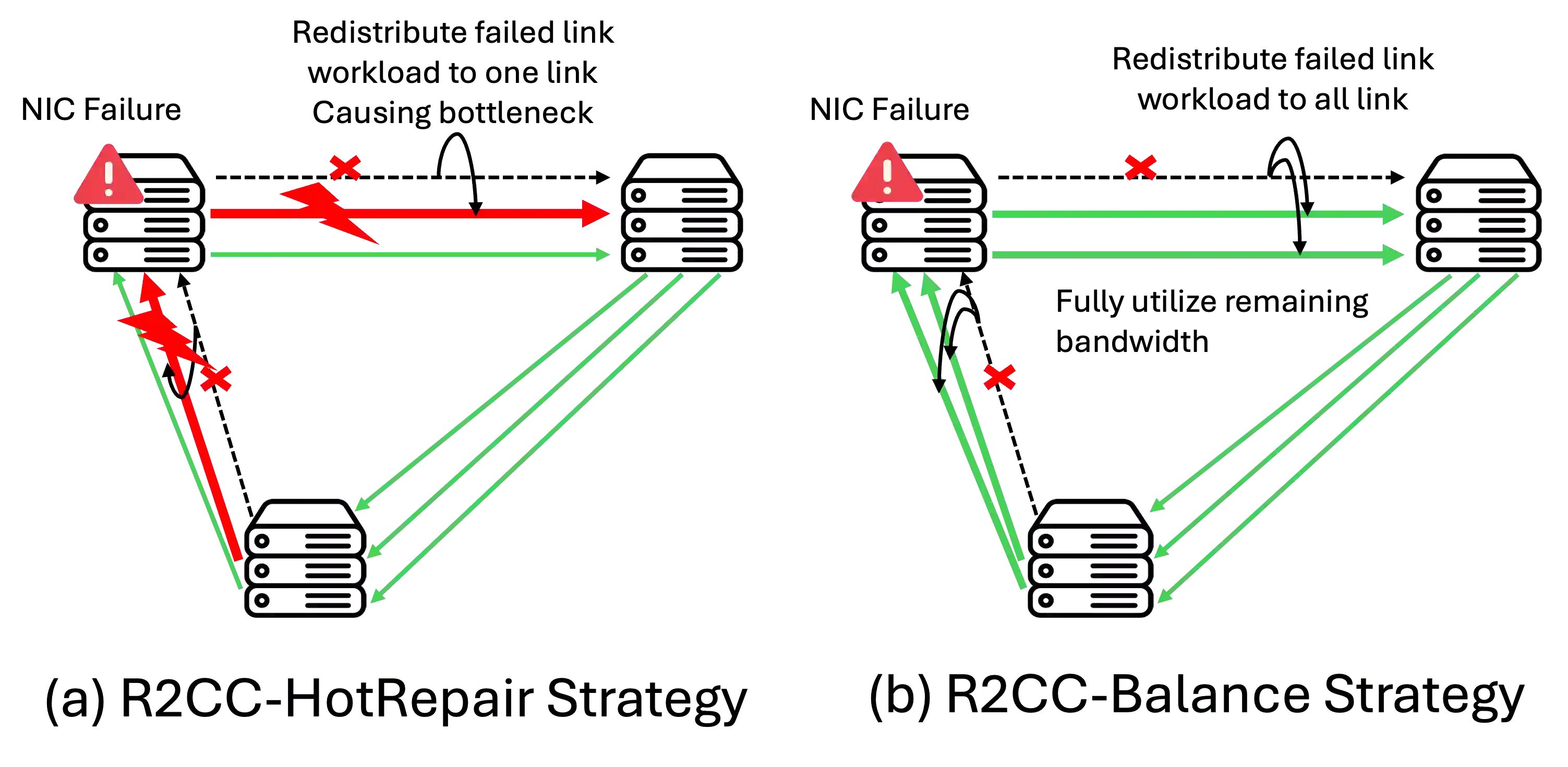
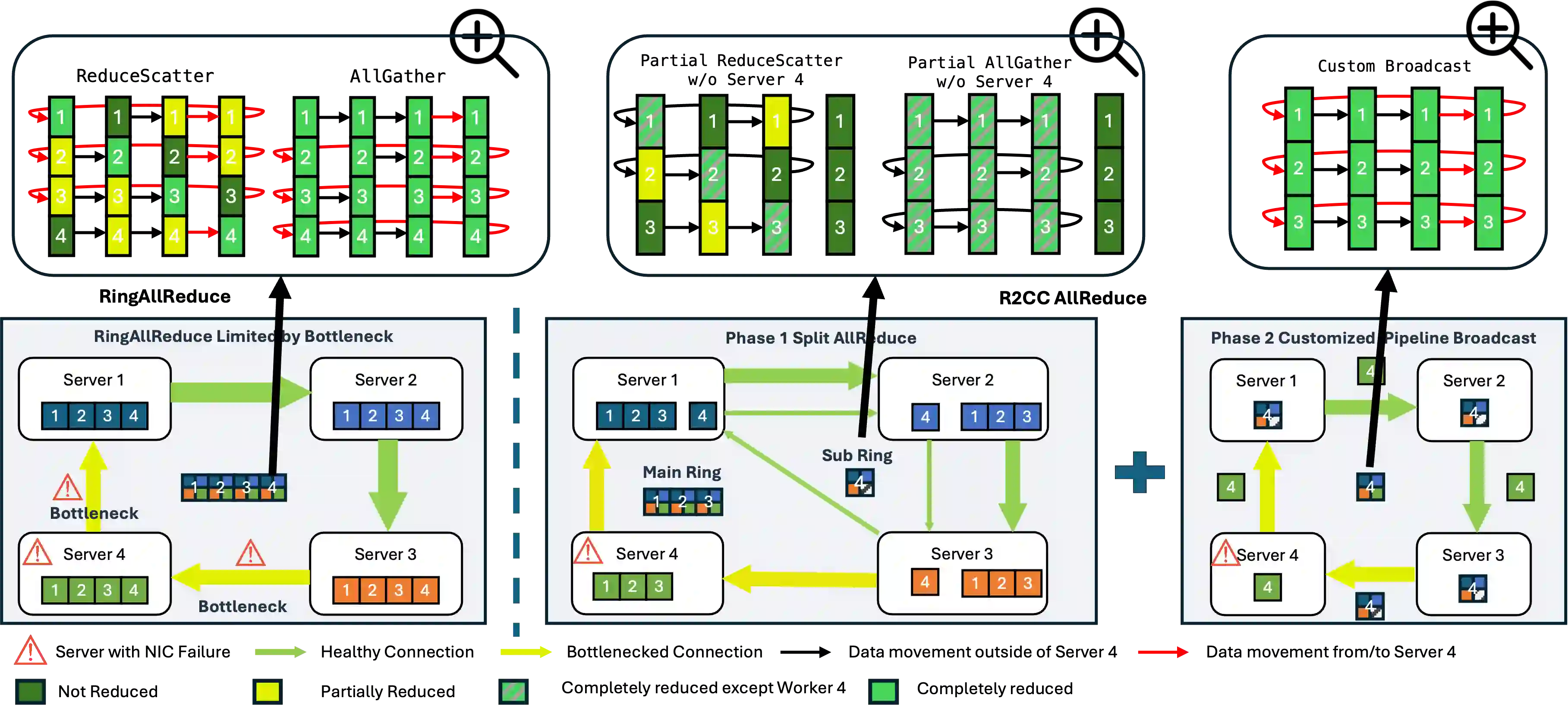
Modern ML training and inference now span tens to tens of thousands of GPUs, where network faults can waste 10--15\% of GPU hours due to slow recovery. Common network errors and link fluctuations trigger timeouts that often terminate entire jobs, forcing expensive checkpoint rollback during training and request reprocessing during inference. We present R$^2$CCL, a fault-tolerant communication library that provides lossless, low-overhead failover by exploiting multi-NIC hardware. R$^2$CCL performs rapid connection migration, bandwidth-aware load redistribution, and resilient collective algorithms to maintain progress under failures. We evaluate R$^2$CCL on two 8-GPU H100 InfiniBand servers and via large-scale ML simulators modeling hundreds of GPUs with diverse failure patterns. Experiments show that R$^2$CCL is highly robust to NIC failures, incurring less than 1\% training and less than 3\% inference overheads. R$^2$CCL outperforms baselines AdapCC and DejaVu by 12.18$\times$ and 47$\times$, respectively.
翻译:现代机器学习训练与推理任务现已扩展至数十至数万块GPU的规模,其中网络故障可因恢复缓慢导致10-15%的GPU时被浪费。常见的网络错误与链路波动会触发超时机制,往往导致整个作业终止,迫使训练过程中进行昂贵的检查点回滚,并在推理时重新处理请求。本文提出R$^2$CCL——一种通过利用多网卡硬件实现无损低开销故障转移的容错通信库。R$^2$CCL通过快速连接迁移、带宽感知的负载重分布以及弹性集体算法,在故障发生时维持任务进展。我们在两台配备8块H100 GPU的InfiniBand服务器上,以及通过模拟数百块GPU并包含多种故障模式的大规模机器学习仿真器中对R$^2$CCL进行了评估。实验表明,R$^2$CCL对网卡故障具有高度鲁棒性,产生的训练开销低于1%,推理开销低于3%。R$^2$CCL分别以12.18$\times$和47$\times$的优势超越了基线方法AdapCC与DejaVu。