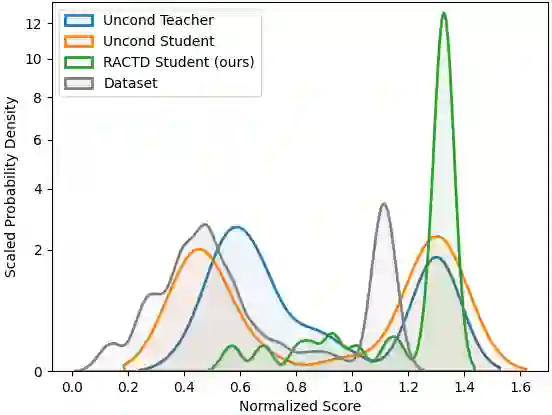
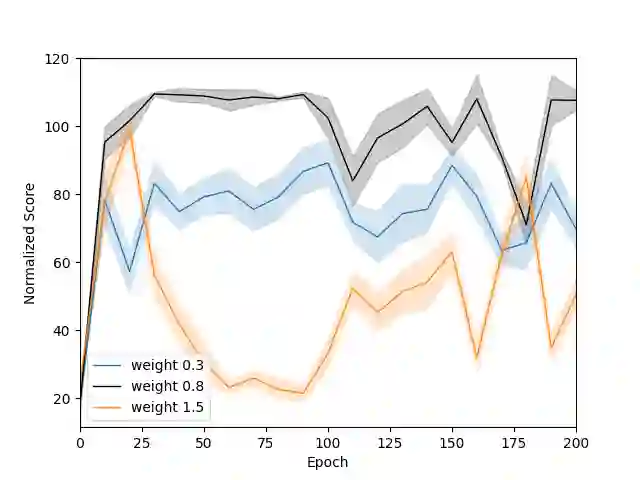
Although diffusion models have achieved strong results in decision-making tasks, their slow inference speed remains a key limitation. While consistency models offer a potential solution, existing applications to decision-making either struggle with suboptimal demonstrations under behavior cloning or rely on complex concurrent training of multiple networks under the actor-critic framework. In this work, we propose a novel approach to consistency distillation for offline reinforcement learning that directly incorporates reward optimization into the distillation process. Our method achieves single-step sampling while generating higher-reward action trajectories through decoupled training and noise-free reward signals. Empirical evaluations on the Gym MuJoCo, FrankaKitchen, and long horizon planning benchmarks demonstrate that our approach can achieve a 9.7% improvement over previous state-of-the-art while offering up to 142x speedup over diffusion counterparts in inference time.
翻译:尽管扩散模型在决策任务中取得了显著成果,但其缓慢的推理速度仍是关键瓶颈。一致性模型虽提供了潜在解决方案,但现有应用于决策的方法要么在行为克隆下受限于次优示范,要么依赖于演员-评论家框架下多个网络的复杂并行训练。本研究提出一种用于离线强化学习的一致性蒸馏新方法,将奖励优化直接融入蒸馏过程。通过解耦训练与无噪声奖励信号,我们的方法在实现单步采样的同时生成更高奖励的动作轨迹。在Gym MuJoCo、FrankaKitchen及长程规划基准上的实证评估表明,本方法较先前最优性能提升9.7%,推理速度较扩散模型实现最高142倍加速。