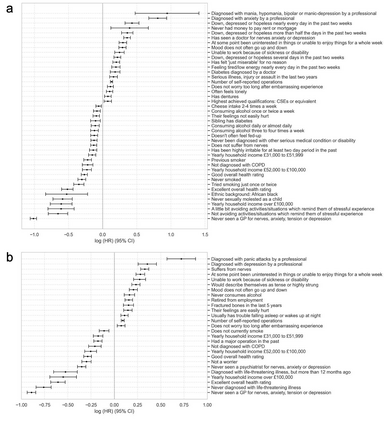
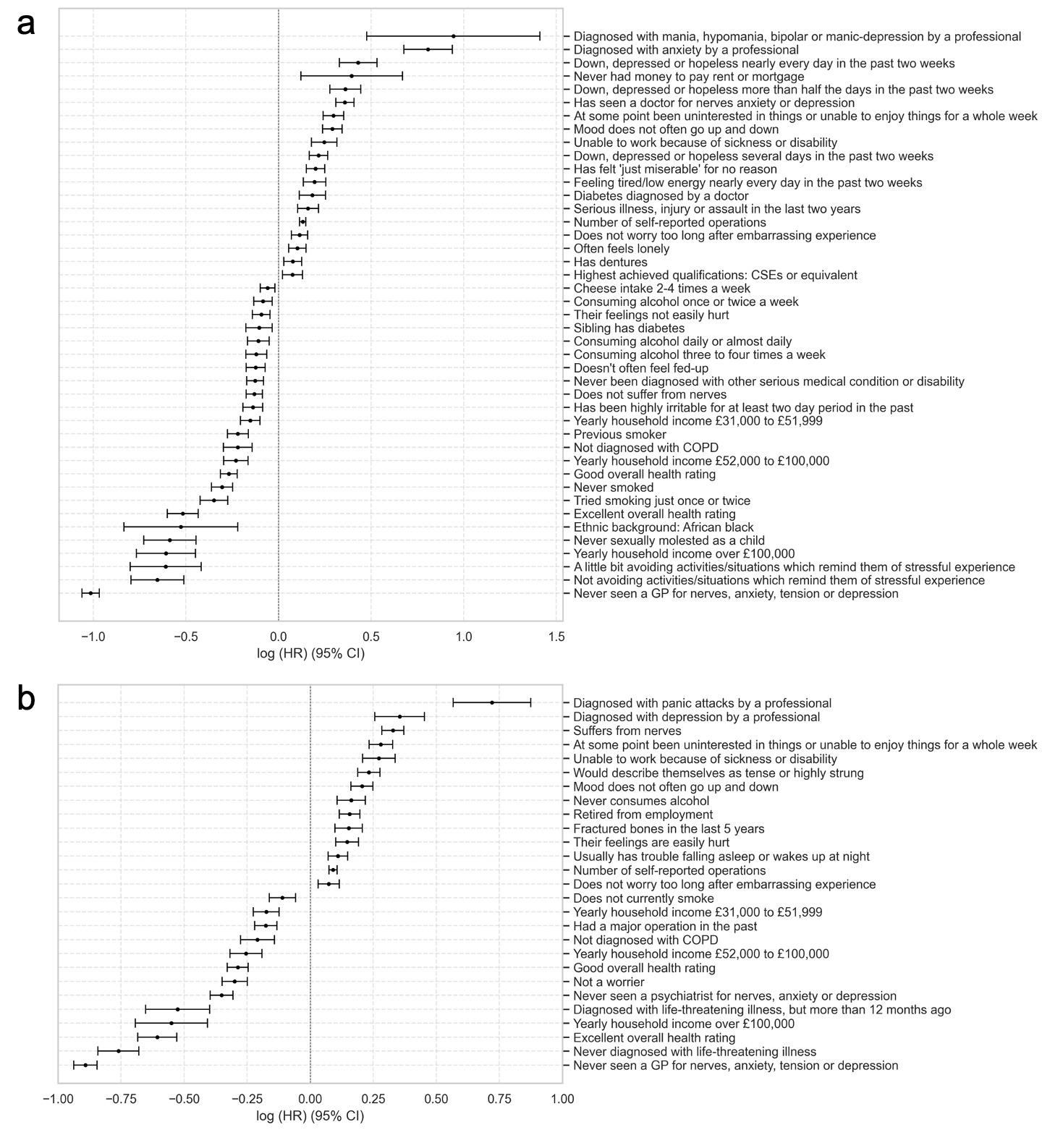
The burden of depression and anxiety in the world is rising. Identification of individuals at increased risk of developing these conditions would help to target them for prevention and ultimately reduce the healthcare burden. We developed a 10-year predictive algorithm for depression and anxiety using the full cohort of over 400,000 UK Biobank (UKB) participants without pre-existing depression or anxiety using digitally obtainable information. From the initial 204 variables selected from UKB, processed into > 520 features, iterative backward elimination using Cox proportional hazards model was performed to select predictors which account for the majority of its predictive capability. Baseline and reduced models were then trained for depression and anxiety using both Cox and DeepSurv, a deep neural network approach to survival analysis. The baseline Cox model achieved concordance of 0.813 and 0.778 on the validation dataset for depression and anxiety, respectively. For the DeepSurv model, respective concordance indices were 0.805 and 0.774. After feature selection, the depression model contained 43 predictors and the concordance index was 0.801 for both Cox and DeepSurv. The reduced anxiety model, with 27 predictors, achieved concordance of 0.770 in both models. The final models showed good discrimination and calibration in the test datasets.We developed predictive risk scores with high discrimination for depression and anxiety using the UKB cohort, incorporating predictors which are easily obtainable via smartphone. If deployed in a digital solution, it would allow individuals to track their risk, as well as provide some pointers to how to decrease it through lifestyle changes.
翻译:在世界上,抑郁症和焦虑症的负担正在上升; 确定面临更大风险的人,开发这些条件的人,将有助于使他们有预防目标,并最终减少医疗负担; 我们开发了10年抑郁和焦虑预测算法,使用40多万英国Biobank(UKB)的全组参与者,没有预先存在的抑郁症或焦虑症,使用数字可获取的信息,开发了10年期抑郁和焦虑症预测算法; 从最初从UKB选出204个变量,处理成大于520个特征,利用Cox比例危害模型进行迭接后后消除,选择了占其预测能力大部分的预测器; 然后,利用Cox和DeepSurv这两种深度神经网络分析方法,对基线和减少的模型进行了抑郁和焦虑问题培训; 基准考克斯模型在抗抑郁症和焦虑症验证数据集上实现了0.813和0.778的一致; 在DeepSurv模型中,分别用0.805和0.77的同步指数进行反复排序; 最终模型通过Scial-Charmillation 进行测试,通过Slishal develrial Sligal Sligal Sligal 进行自我定位,从而进行测试,最终测试,将数据定位为Cal-